
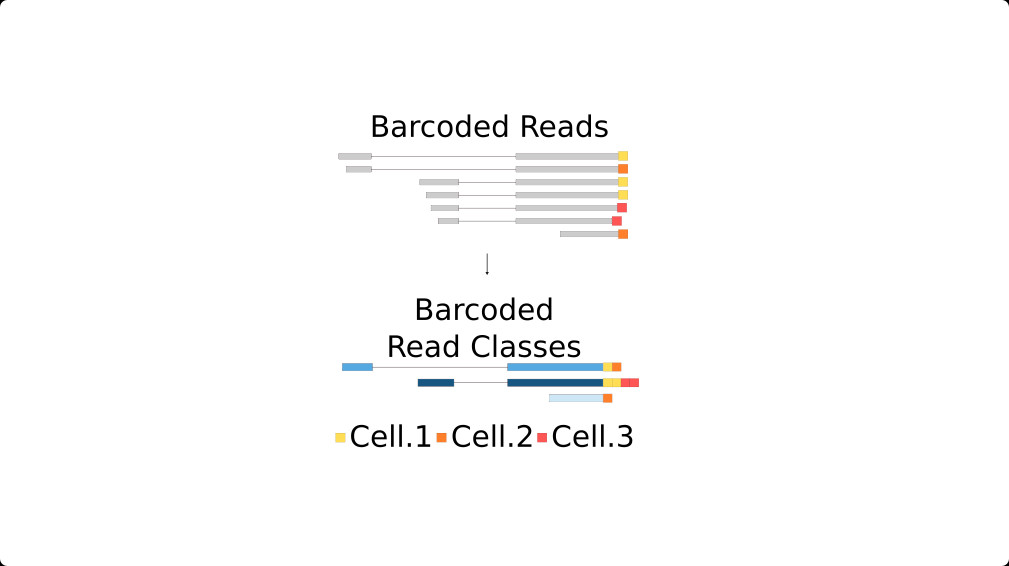
The key challenges were dimensionality (>200k transcripts x thousands cells) and estimation of transcript expression. The dimensionality we handle by optimising the representation of reads in memory using barcoded read classes, making transcript discovery and read-to-transcript assignment very fast
Comments