
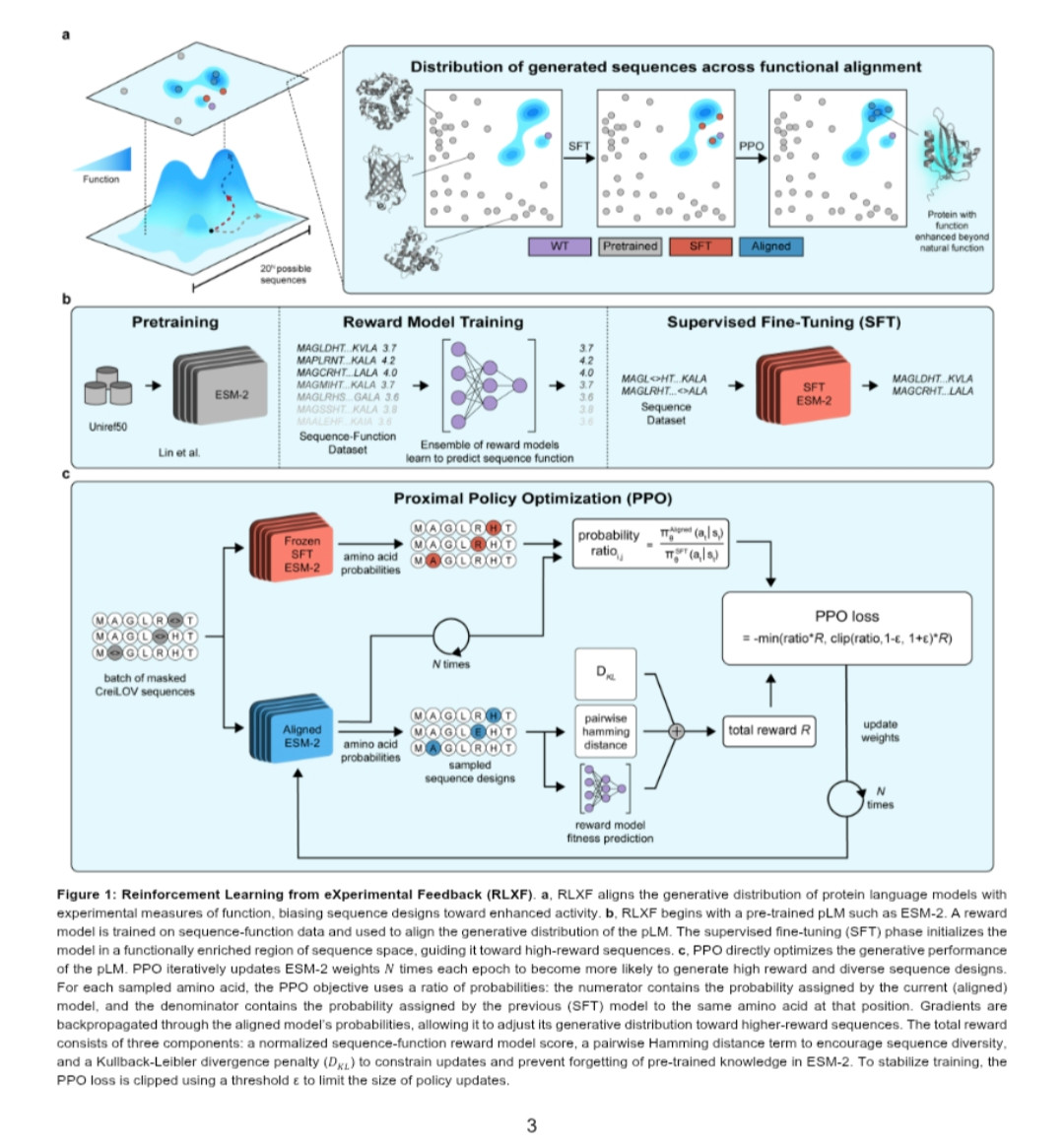
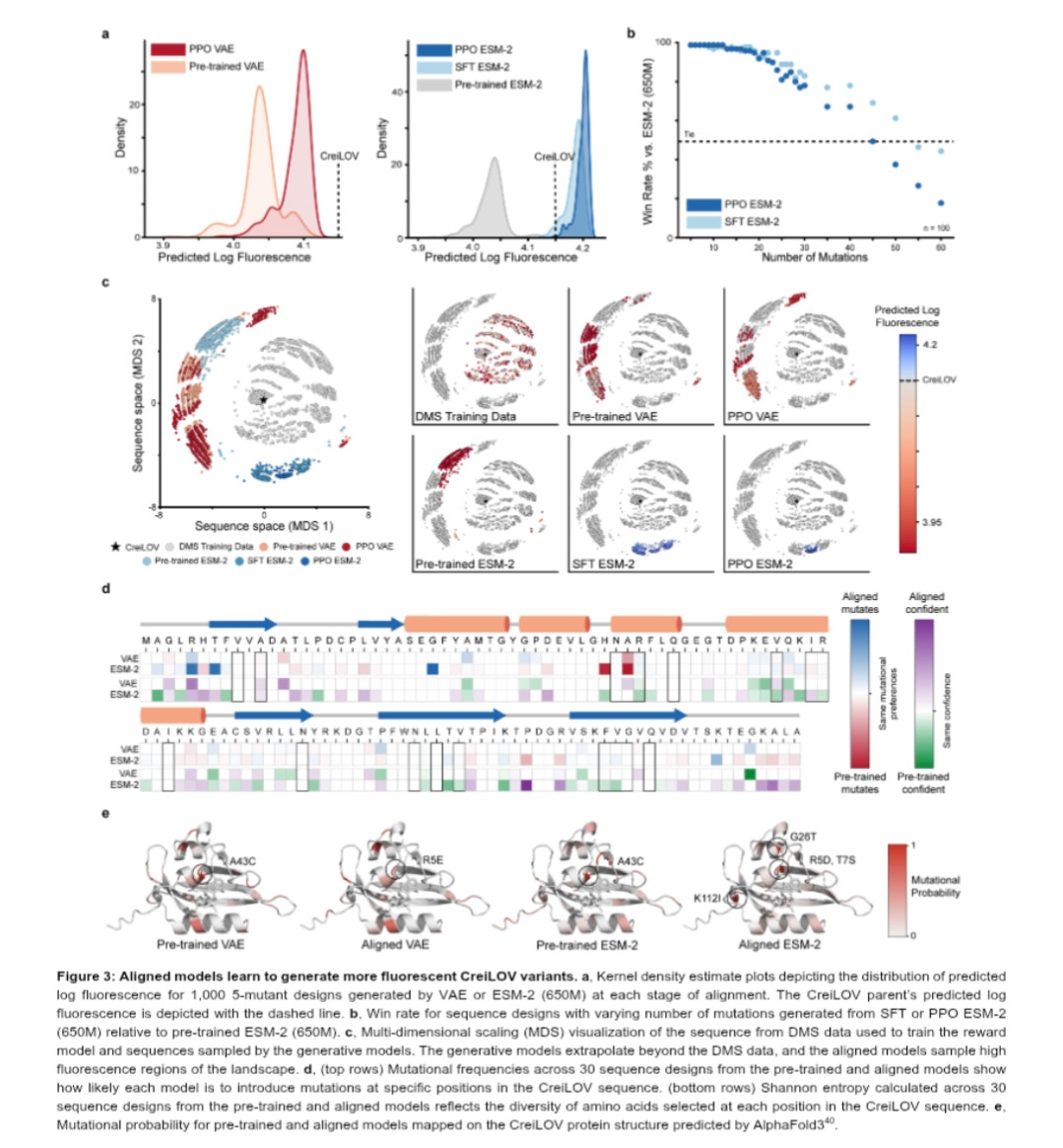
Reinforcement learning with experimental feedback (RLXF) shifts protein language models so that they generate sequences with improved properties
@nathanielblalock.bsky.social @philromero.bsky.social
https://www.biorxiv.org/content/10.1101/2025.05.02.651993v1
@nathanielblalock.bsky.social @philromero.bsky.social
https://www.biorxiv.org/content/10.1101/2025.05.02.651993v1
1 / 2
Comments