
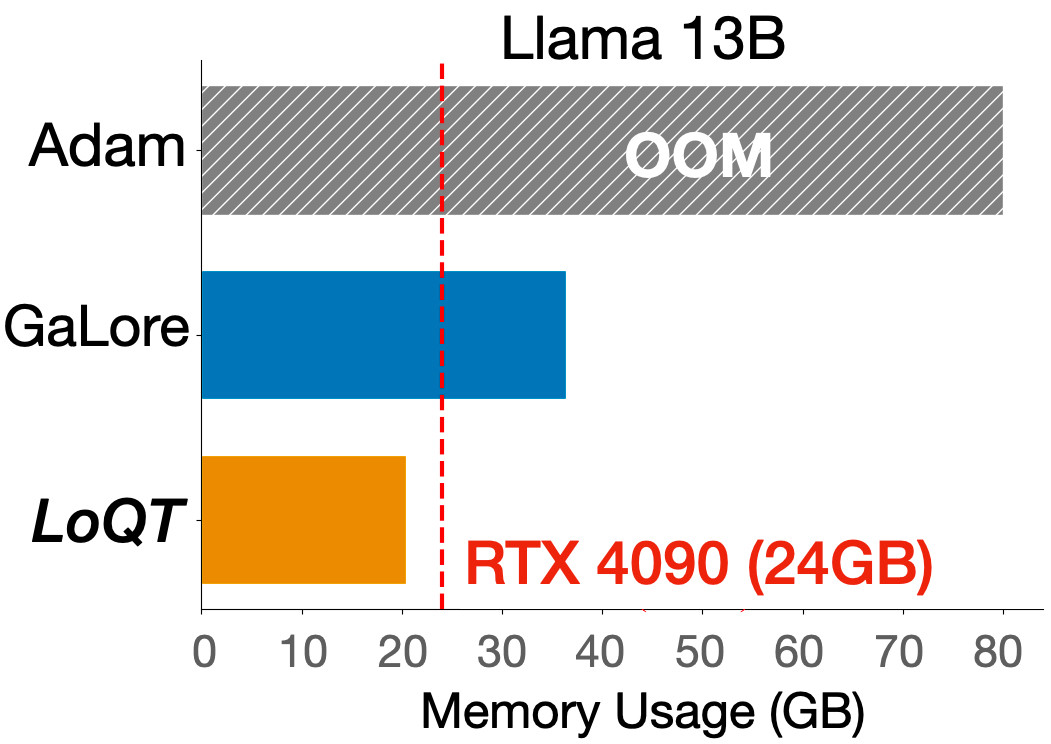
Ever wanted to train your own 13B Llama2 model from scratch on a 24GB GPU? Or fine-tune one without compromising performance compared to full training? 🦙
You now can, with LoQT: Low-Rank Adapters for Quantized Pretaining! https://arxiv.org/abs/2405.16528
1/4
You now can, with LoQT: Low-Rank Adapters for Quantized Pretaining! https://arxiv.org/abs/2405.16528
1/4
Comments
This reduces memory for gradients, optimizer states, and weights—even when pretraining from scratch.
2/4
We show LoQT works for both LLM pre-training and downstream task adaptation📊.
3/4
Great collaboration with @mabeto5p, @mjkastoryano, @sergebelongie.bsky.social , @vesteinns.bsky.social
Code: https://github.com/sebulo/LoQT 💻
Paper: https://arxiv.org/abs/2405.16528 📄
This research was funded by @DataScienceDK, and @AiCentreDK and is a collaboration between @DIKU_Institut, @ITUkbh, and @csaudk