🧵 Heard all the buzz around distilling from OpenAI models? Check out @jifanz's latest work SIEVE - showing how strategic distillation can make LLM development radically more cost-effective while matching quality.
Comments
Log in with your Bluesky account to leave a comment
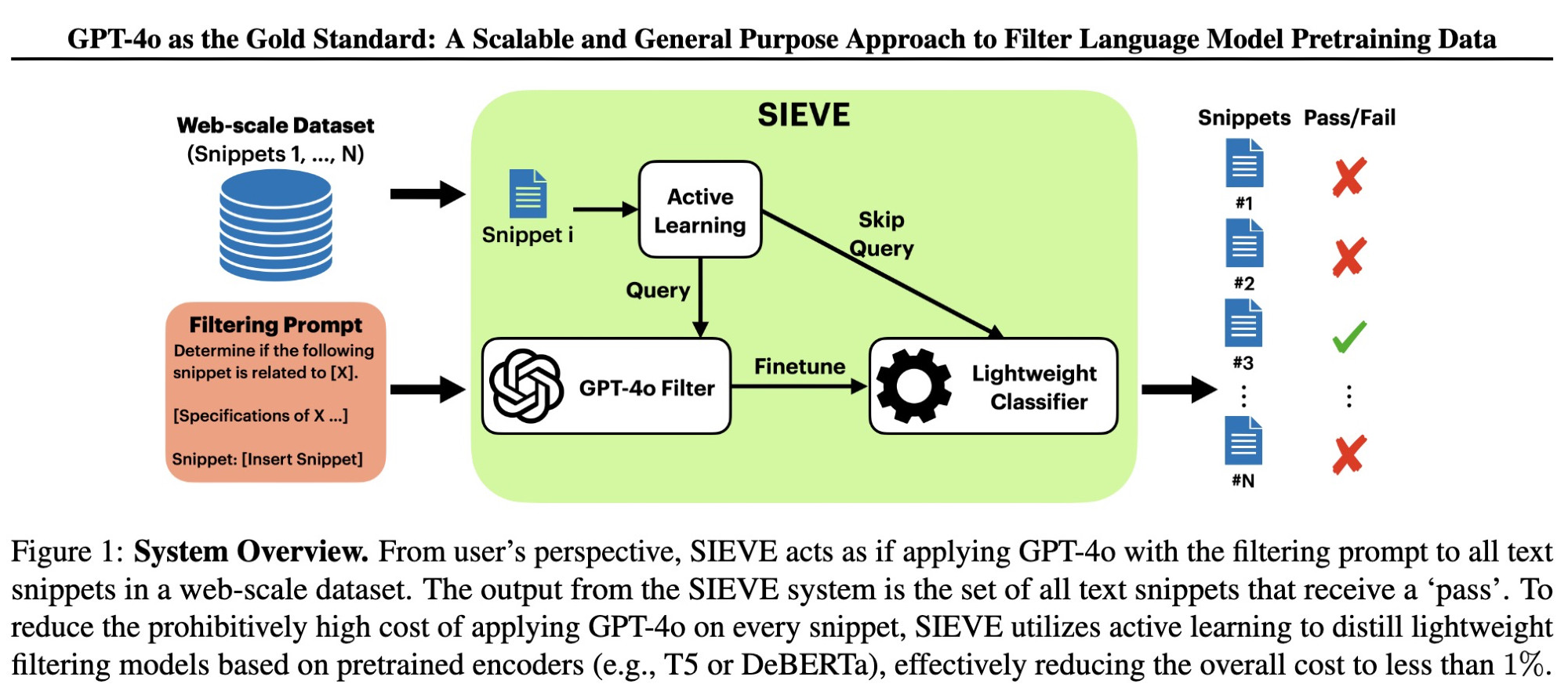
SIEVE distills GPT-4's data filtering capabilities into lightweight models at <1% of the cost. Not just minor improvements - we're talking 500x more efficient filtering operations.
Why does this matter? High-quality data is the bedrock of LLM training. SIEVE enables filtering trillions of web data for specific domains like medical/legal text with customizable natural language prompts.
SIEVE improves upon existing quality filtering methods in the DataComp-LM challenge, producing better LLM pretraining data that led to improved model performance.
This work is part of Jifan's broader research on efficient ML training, from active learning to label-efficient SFT for LLMs.
Jifan’s on the industry job market now, and his expertise in efficient training, distillation, and data curation couldn't be more timely. Feel free to reach out to him at [email protected].
📄 Paper: https://arxiv.org/abs/2410.02755

Comments
This work is part of Jifan's broader research on efficient ML training, from active learning to label-efficient SFT for LLMs.
📄 Paper: https://arxiv.org/abs/2410.02755