
This makes me think that the user-LLM feedback loop might be the ultimate inference time scaling we need. Fast loop = more prompting and refinement with the user aware of each step = better responses (assume user can verify it). Maybe Gemini flash as a consumer product still wins
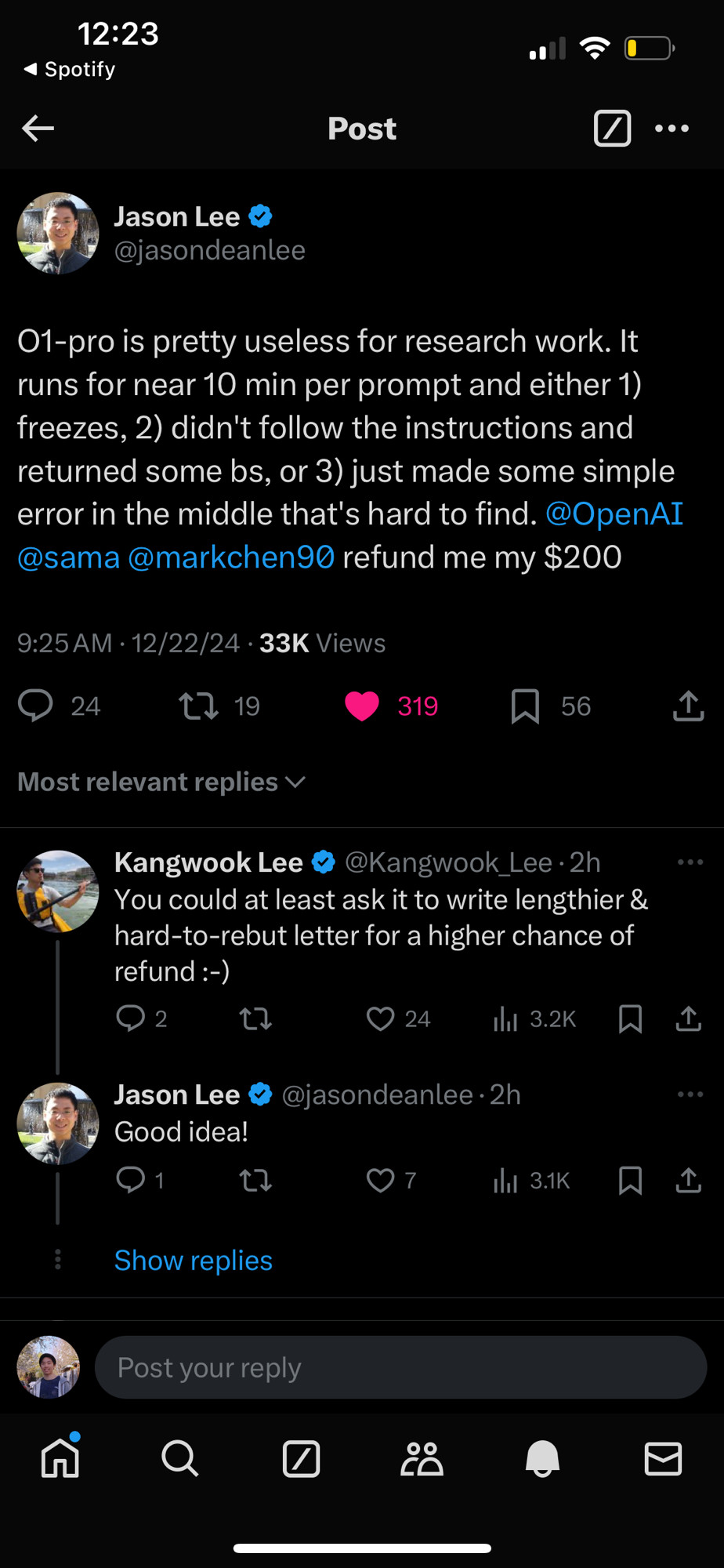
Comments