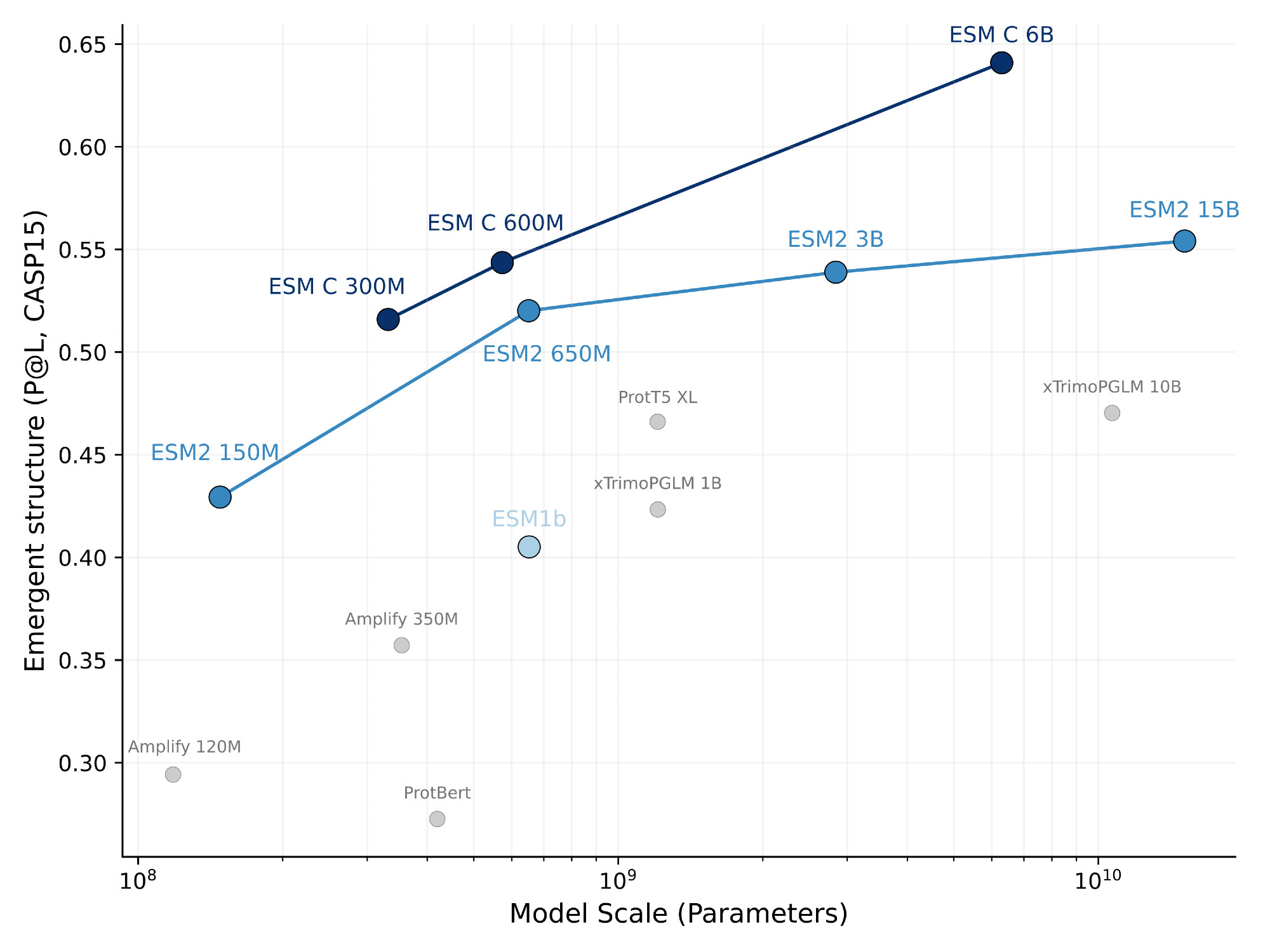
Information about protein structure improves predictably with increasing training compute, demonstrating linear scaling across multiple orders of magnitude.
We overtrained ESM C 300M and 600M beyond the compute-optimal point predicted by the scaling curves.

Comments
We overtrained ESM C 300M and 600M beyond the compute-optimal point predicted by the scaling curves.