
I began by replicating .txt's results using LLaMA-3-8B-Instruct (the model considered in the rebuttal).
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
Comments
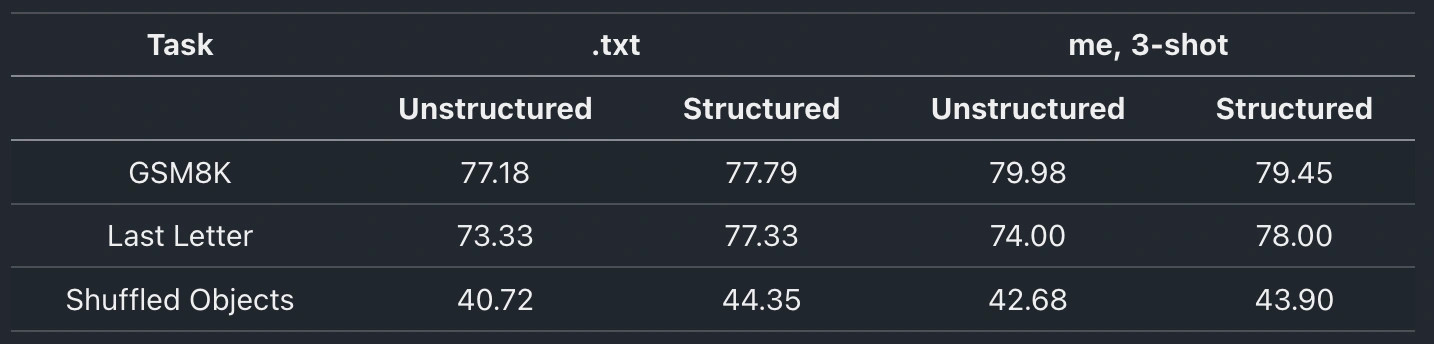
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
But it’s clear to me that neither structured nor unstructured outputs are always better, and choosing one or the other can often make a difference.
Test things yourself. Run your own evals and decide.
Once or twice per month I write a technical article about AI here: https://subscribe.dylancastillo.co/