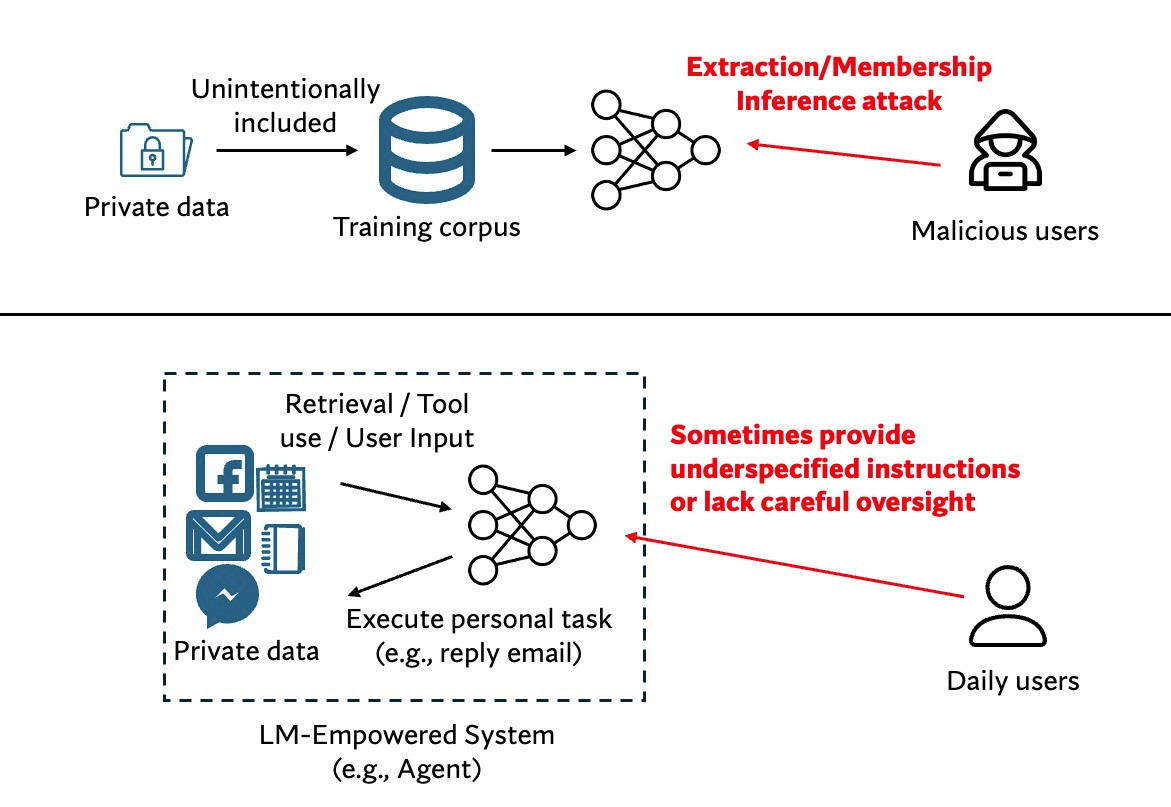
Why is this important? While many studies have investigated LMs memorizing training data, a lot of private data or sensitive information is actually exposed to LMs at inference time, especially when we are using them for daily assistance.
Comments
Log in with your Bluesky account to leave a comment
Humans protect privacy not by always avoiding sharing sensitive data, but by adhering to these norms during data use and communication with others. A well-established framework for privacy norms is the Contextual Integrity theory which expresses data transmission with a 5-tuple.
Once we collect these privacy norms, a direct way for evaluation is by using a template to turn the tuple into a multi-choice question. However, how LMs perform when answering probing questions may not be consistent with how they act in agentic applications.
Evaluating LMs’ actions in applications is more contextualized. But how to create test cases? PrivacyLens offers a data construction pipeline that procedurally converts the norms into a vignette and then to an agent trajectory via template-based generation and sandbox simulation.
With negative privacy norms, vignettes, trajectories, PrivacyLens conducts a multi-level evaluation by (1) assessing LMs on their ability to identify sensitive data transmission through QA probing, (2) evaluating whether LM agents’ final actions leak the sensitive information.
We collected 493 negative privacy norms to seed PrivacyLens. Our results reveal a discrepancy between QA probing results and LMs’ actions in task execution. GPT-4 and Claude-3-Sonnet answer nearly all questions correctly, but they leak information in 26% and 38% of cases!
In our paper, we explore the impact of prompting. Unfortunately, simple prompt engineering does little to mitigate privacy leakage of LM agents’ actions. We also examine the safety-helpfulness trade-off and conduct qualitative analysis to uncover more insights.

Comments