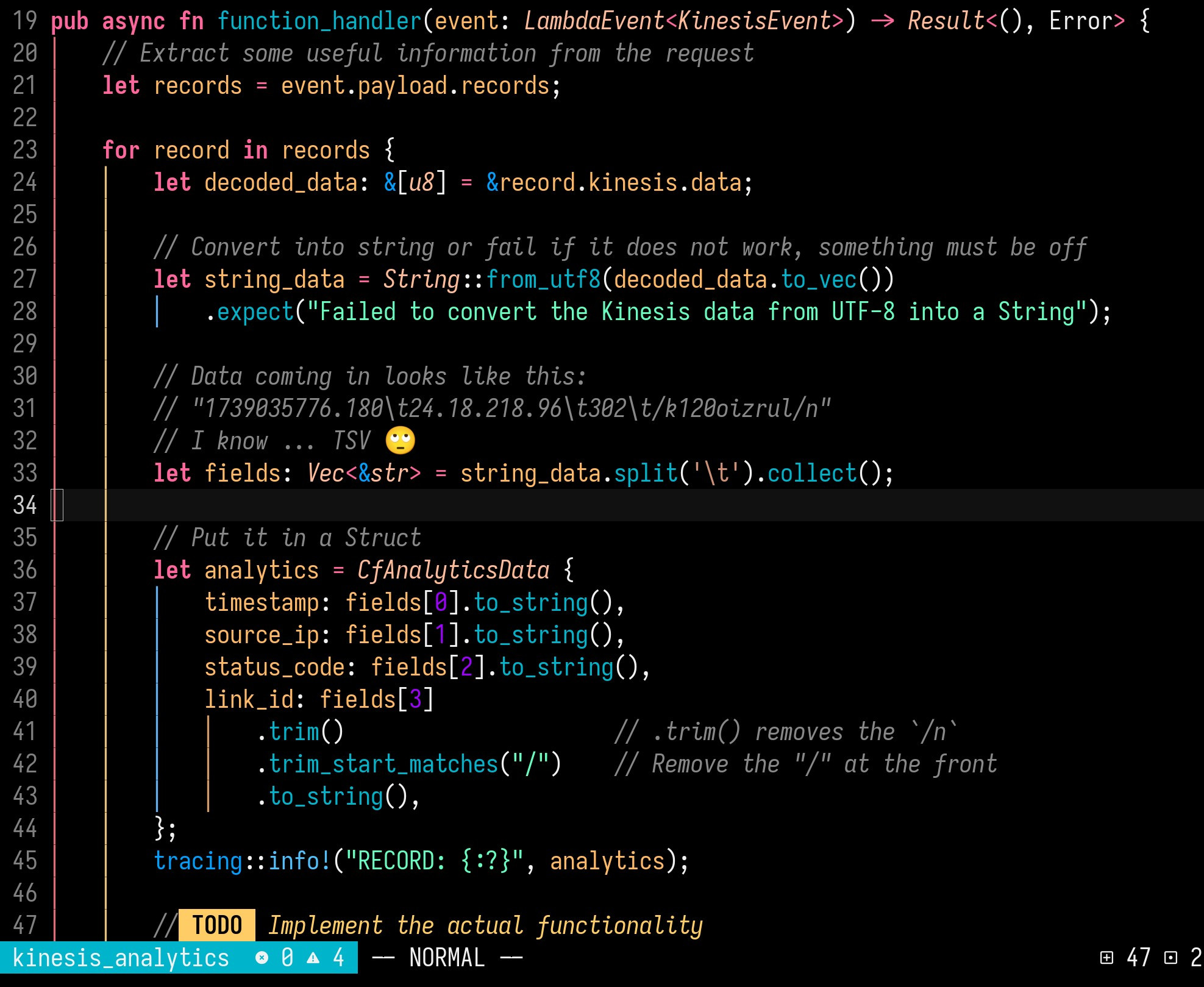
It’s odd, yes, and I‘m not sure why it was probably chosen. But I guess the main reason could eventually be that you can parse/split it very efficiently in probably all runtimes, e.g. compared to JSON…
You are probably right! For me JSON seem so much easier to parse / deserialize! But I also guess that JSON has a lot more overhead in the terms of raw bytes being sent over.

Comments
https://docs.ownstats.com/architecture/processing-layer
If it helps, there’re a few npm packages that do it.
https://www.npmjs.com/package/tsv-json