
OpenAI announced a new RL finetuning API. You can do this on open models w the repo we used to train Tulu 3.
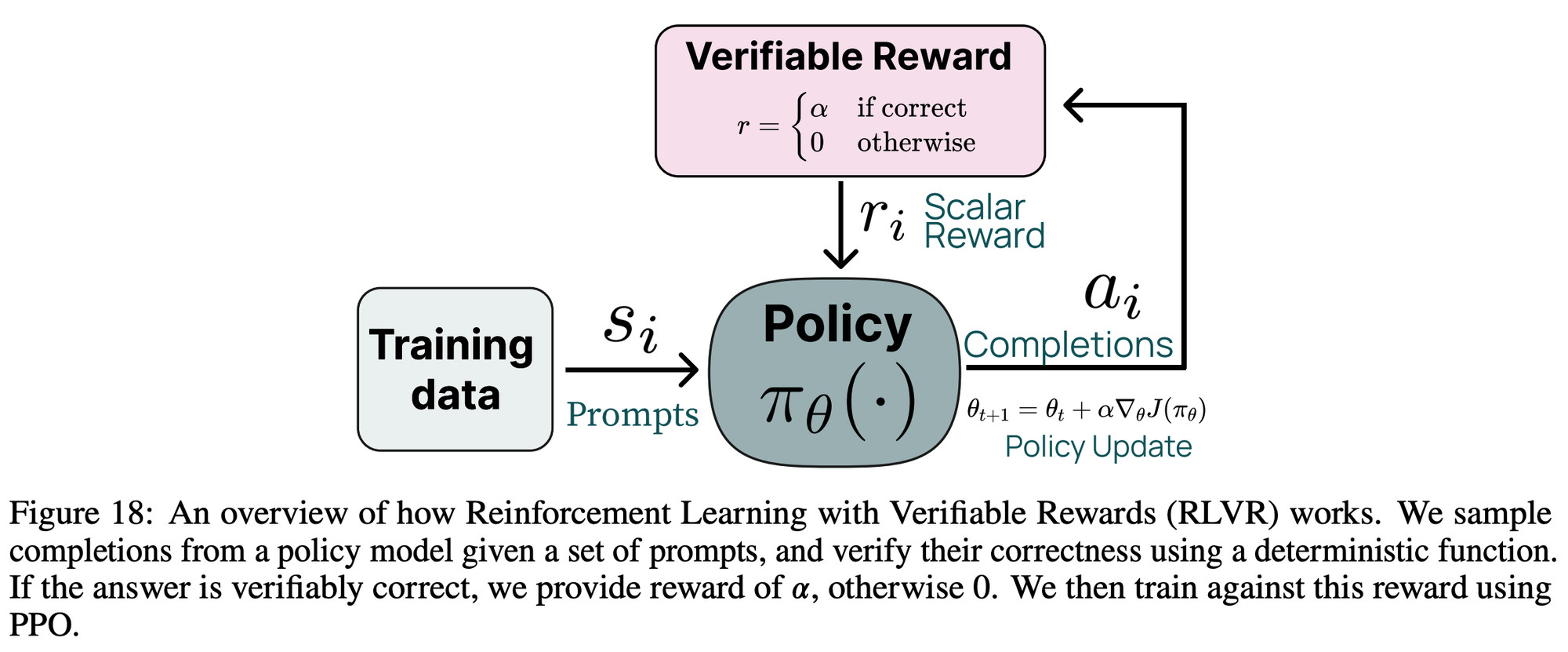
Expanding reinforcement learning with verifiable rewards to more domains and with better answer extraction and to more domains in our near roadmap.
https://buff.ly/3V4JEIJ
Expanding reinforcement learning with verifiable rewards to more domains and with better answer extraction and to more domains in our near roadmap.
https://buff.ly/3V4JEIJ
Comments