
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
Comments
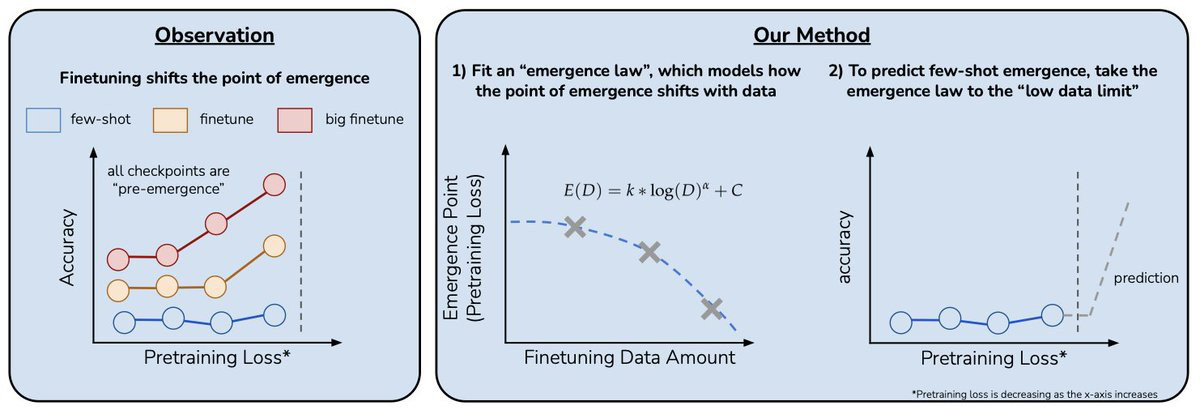
given access to LLMs that have random few-shot accuracy on a task, can we predict the point in scaling (e.g., pretraining loss) at which performance will jump up beyond random-chance?
finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable LLMs, and the magnitude of this shift is modulated by the amount of finetuning data.
We find that our emergence law can accurately predict the point of emergence up to 4x the FLOPs in advance.
1) cheaply assessing pretraining data quality (left).
2) predicting more complex capabilities, closer to those of future frontier models, using the difficult APPS coding benchmark (right).
.
An early version of this work also appeared in COLM 2024.
Paper link: https://arxiv.org/abs/2411.16035