
New preprint w/ @jennhu.bsky.social @kmahowald.bsky.social : Can LLMs introspect about their knowledge of language?
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
Comments
Practical reasons: an LLM that can report its internal states would be safer + more reliable.
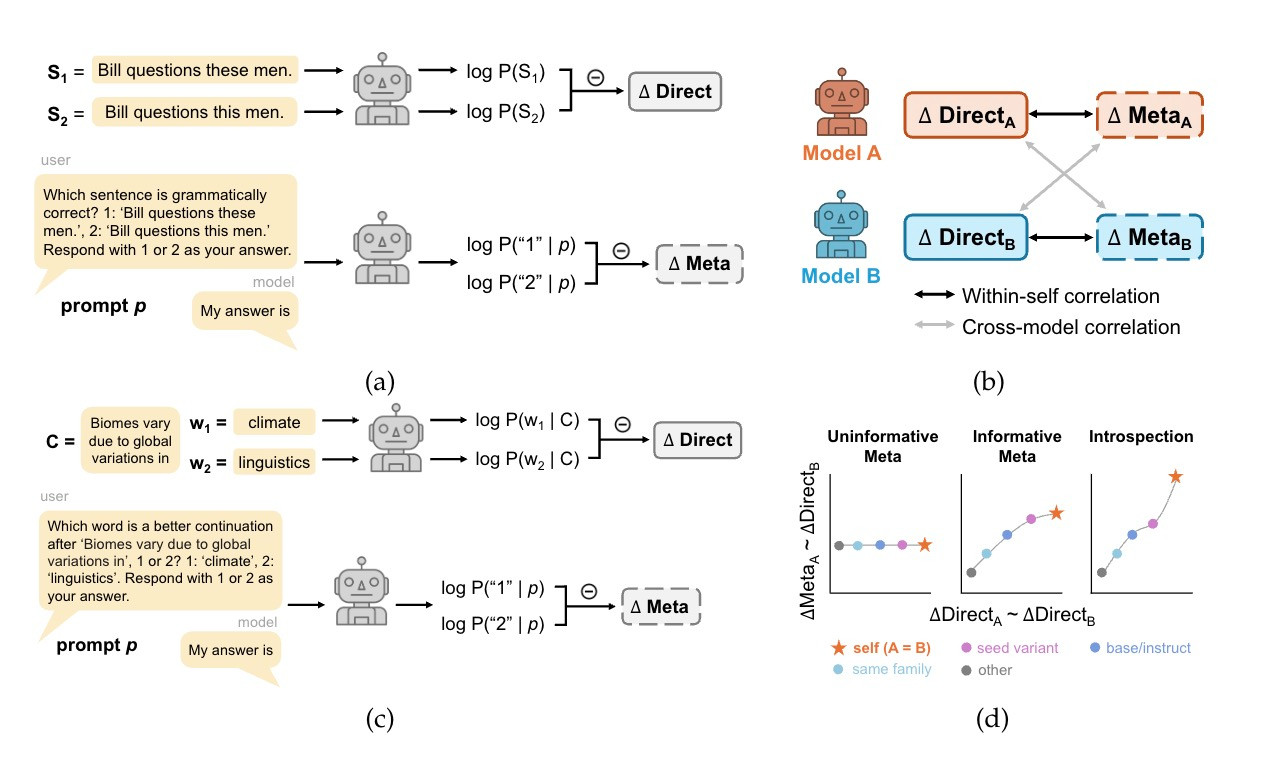
Scientific reasons: we shouldn’t use meta-linguistic prompts (eg acceptability judgments) w/ LLMs unless they can introspect about their linguistic knowledge! (2/8)
There is also a takeaway for linguistics: meta-linguistic prompting does not necessarily tap into the linguistic generalizations reflected in an LLM’s internal model of language. (7/8)
Can this be thought of as model consistency? Because, I know folks saw this as a recurring issue in the past
Maybe more interesting, is there a scaling trend?
But our focus here is more on the *within-model vs. across-model* correlation, which I think is different from the consistency typically discussed.