
New paper!
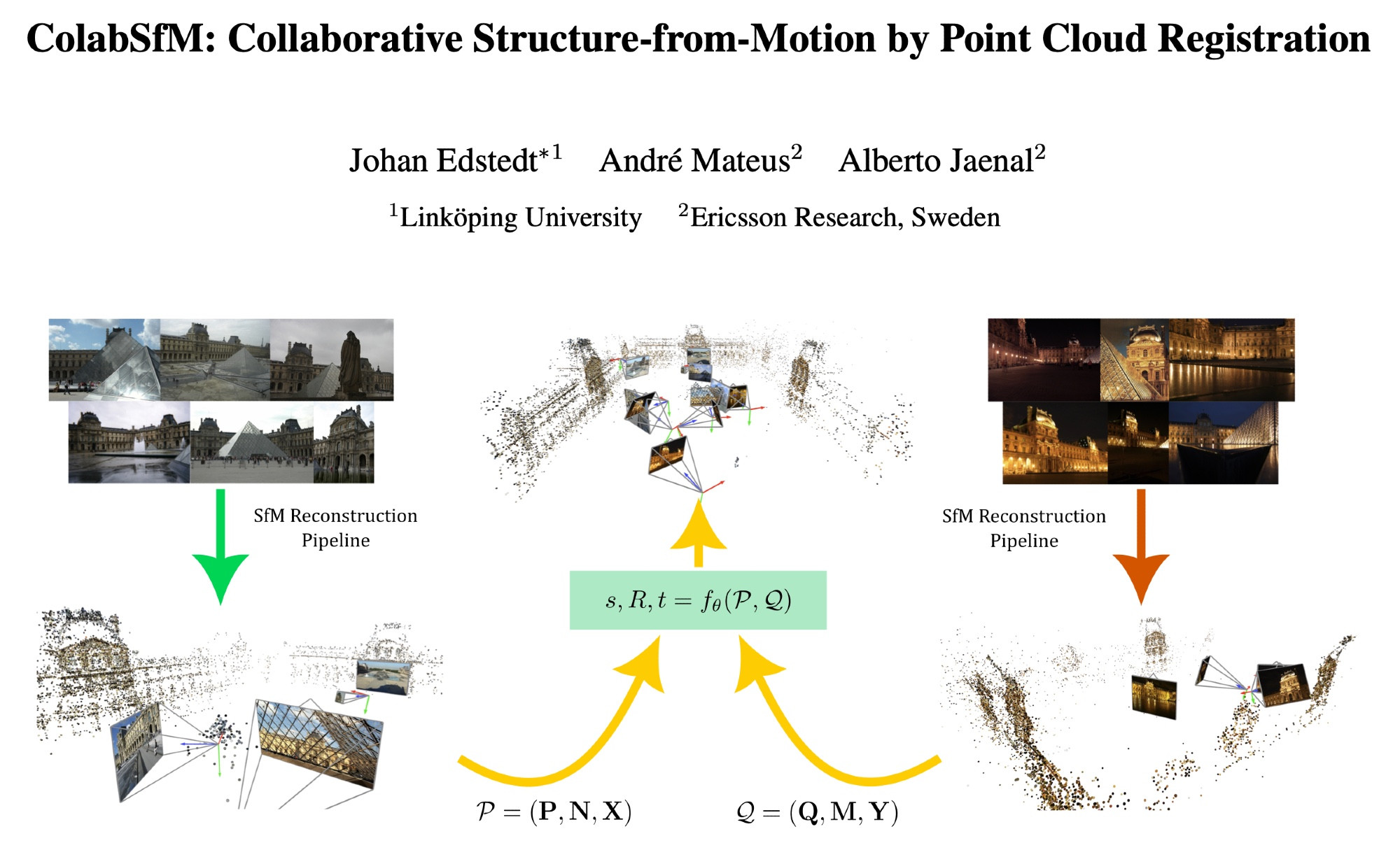
We merge SfM reconstructions with point cloud registration.
Link: https://arxiv.org/abs/2503.17093
Code: Not yet public, but coming later.
We merge SfM reconstructions with point cloud registration.
Link: https://arxiv.org/abs/2503.17093
Code: Not yet public, but coming later.
Comments
Not getting finger muscle cramps from writing all those papers?
Regarding keypoint detectors: I think it's basically forced to, because we downsample the clouds. As long as coverage is similar it should work.
Regarding cramps: It's been quite a while since previous first author pub, and somehow they came all at once.
Imo they destroy way too much information, but still it kind of just works.
You need to be aware of limitations though.
Unfortunately, this is not very simple unless you have shared images between reconstructions, and is a common issue on the COLMAP GitHub ;)
For example, if we can make strong assumptions on the scene, see https://openaccess.thecvf.com/content_iccv_2015/papers/Cohen_Merging_the_Unmatchable_ICCV_2015_paper.pdf, merging is possible.
However, this only works in these very constrained cases.
Yes, this works fine, but gives other constraints.
Now you instead need both reconstructions to use the same detector and descriptor, and perform a rather complex image retrieval pipeline.
This solves the descriptor compatibility problem, but still requires the same detector, and still involves a complex pipeline.
Can't we just get rid of these pesky descriptors?
Well, yes. People have looked into this (https://arxiv.org/abs/2203.12979), but still in the context of localization, and still requiring the same keypoint detector.
However, the question remains, how do you get training data for this task?