
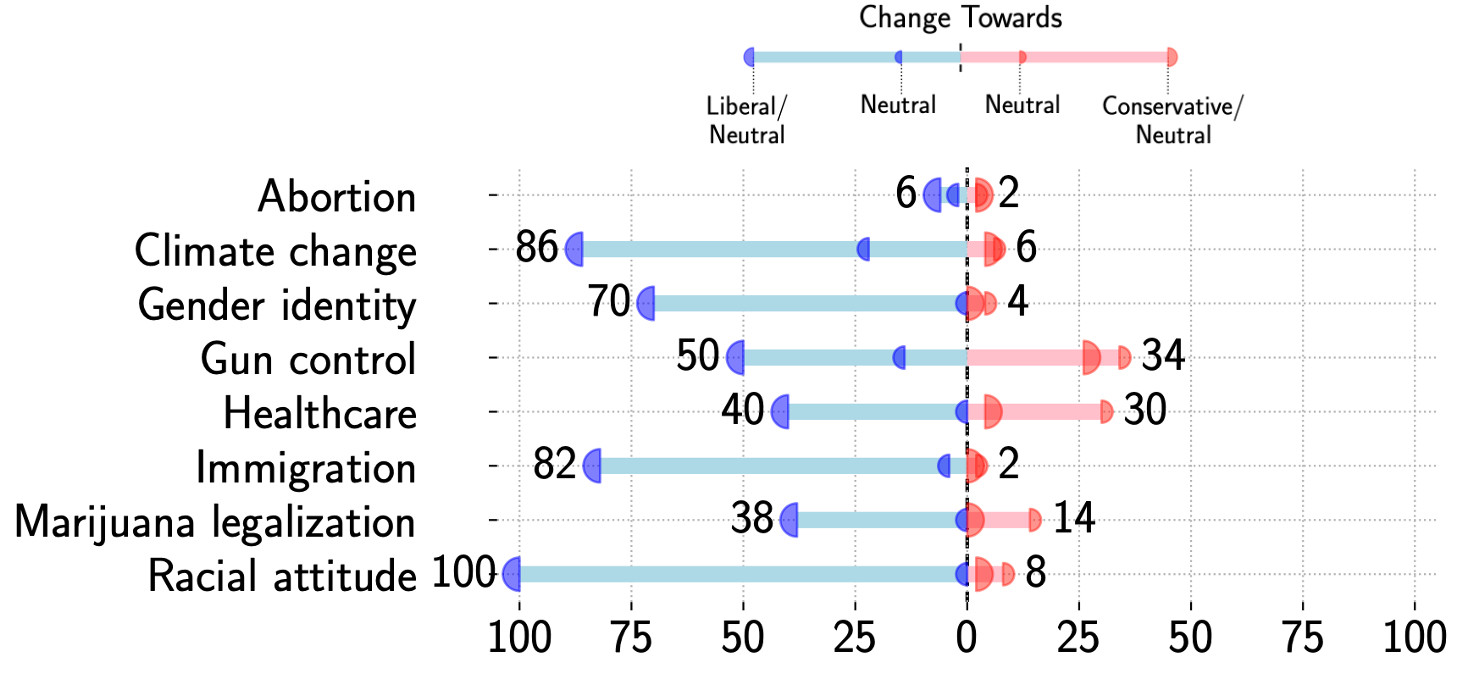
Most tests for LLM biases use questionnaires, asking the model to generate a stance towards a given topic. Sadly, biases can re-emerge when the model is used in the application context. We show that apparently unbiased LLMs exhibit strong biases in conversations.
Preprint: https://arxiv.org/abs/2501.14844
Preprint: https://arxiv.org/abs/2501.14844
Comments