
The "Self-Extend" paper http://arxiv.org/abs/2401.01325 promises magic for your LLMs: extending the context window beyond what they were trained on. You can take an LLM trained on 2000 token sequences, feed it 5000 tokens and expect it to work. Thread 🧵
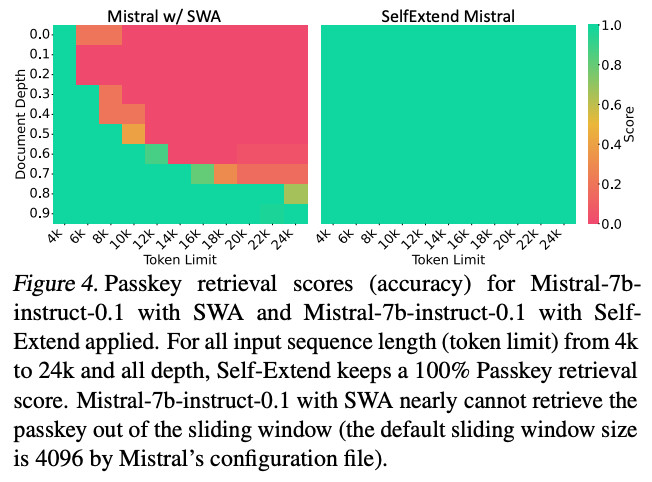
(SWA below=sliding window...
(SWA below=sliding window...
Comments
(scaling + normalization ignored for simplicity)