
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: https://arxiv.org/abs/2503.01174
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: https://arxiv.org/abs/2503.01174
Comments
In human dialogue, we listen, speak, and backchannel in real-time.
Similarly the AI should know when to listen, speak, backchannel, interrupt, convey to the user when it wants to keep the conversation floor and address user interruptions
(2/9)
Recent audio FMs claim to have conversational abilities but limited efforts to evaluate these models on their turn taking capabilities.
(3/9)
Moshi: small gaps, some overlap—but less than natural dialogue
Cascaded: higher latency, minimal overlap.
(4/9)
Moshi generates overlapping speech—but is it helpful or disruptive to the natural flow of the conversation? 🤔
(5/9)
Strong OOD generalization -> a reliable proxy for human judgment!
No need for costly human judgments—our model judges the timing of turn taking events automatically!
(6/9)
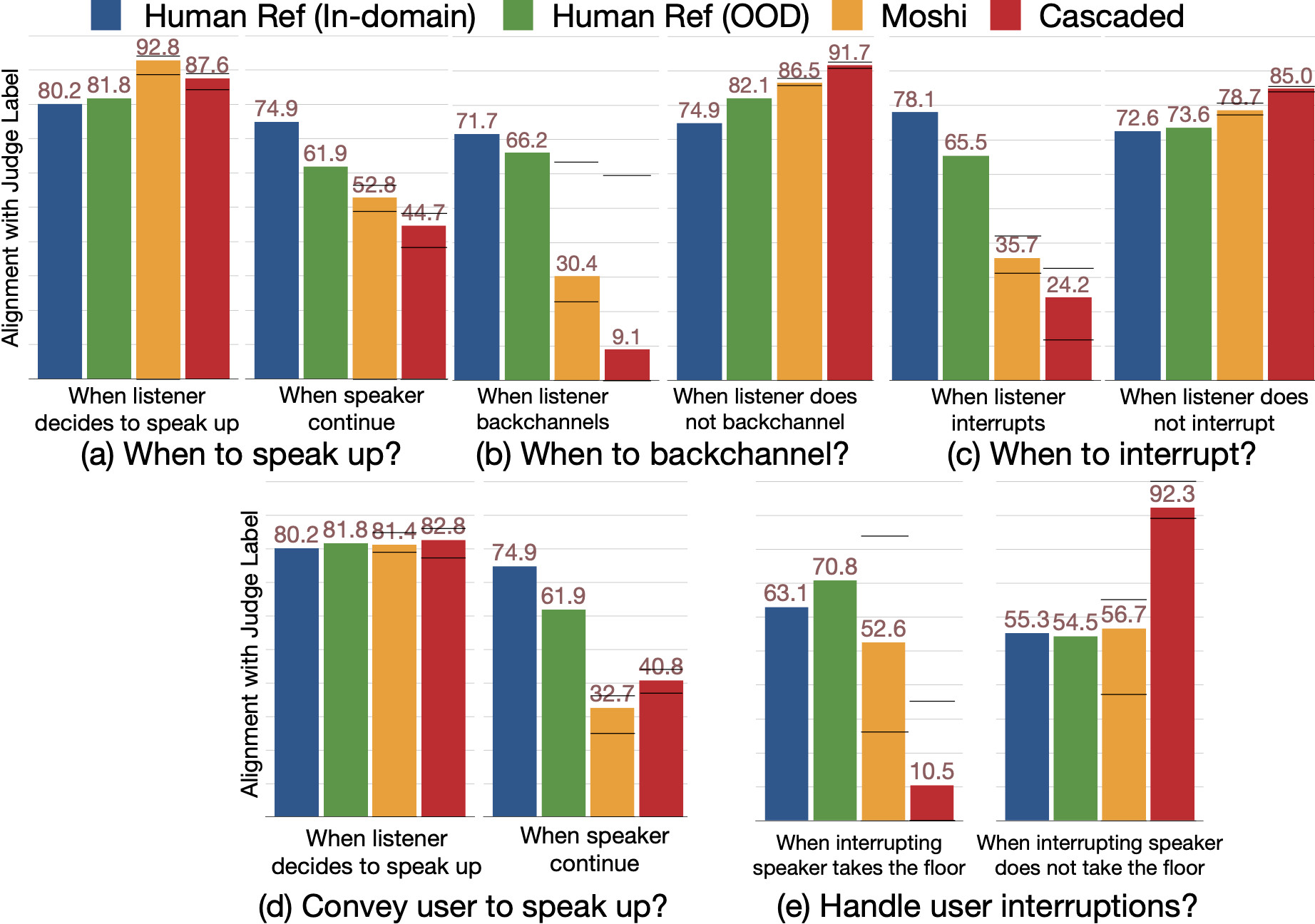
❌ Both systems fails to speak up when they should and do not give user enough cues when they wants to keep conversation floor.
❌ Moshi interrupt too aggressively.
❌ Both systems rarely backchannel.
❌ User interruptions are poorly managed.
(7/9)