
TRecViT: A Recurrent Video Transformer
https://arxiv.org/abs/2412.14294
Causal, 3× fewer parameters, 12× less memory, 5× higher FLOPs than (non-causal) ViViT, matching / outperforming on Kinetics & SSv2 action recognition.
Code and checkpoints out soon.
https://arxiv.org/abs/2412.14294
Causal, 3× fewer parameters, 12× less memory, 5× higher FLOPs than (non-causal) ViViT, matching / outperforming on Kinetics & SSv2 action recognition.
Code and checkpoints out soon.
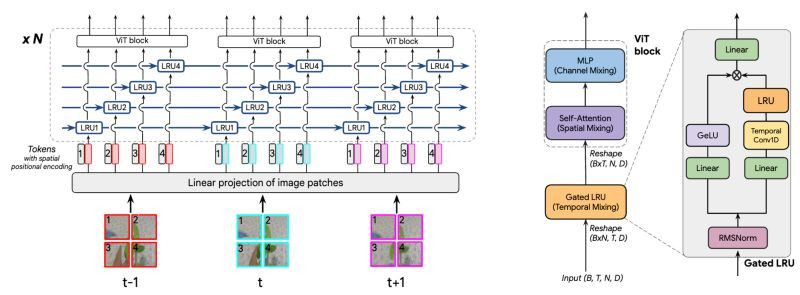
Comments
Viorica Pătrăucean, Xu Owen He, Joseph Heyward, Chuhan Zhang, Mehdi S. M. Sajjadi, George-Cristian Muraru, Artem Zholus, Mahdi Karami, Ross Goroshin, Yutian Chen, Simon Osindero, João Carreira, Razvan Pascanu
Original post:
https://www.linkedin.com/posts/viorica-patraucean-581a7131_super-excited-to-share-our-recent-work-on-activity-7282805324481196032-CtX4