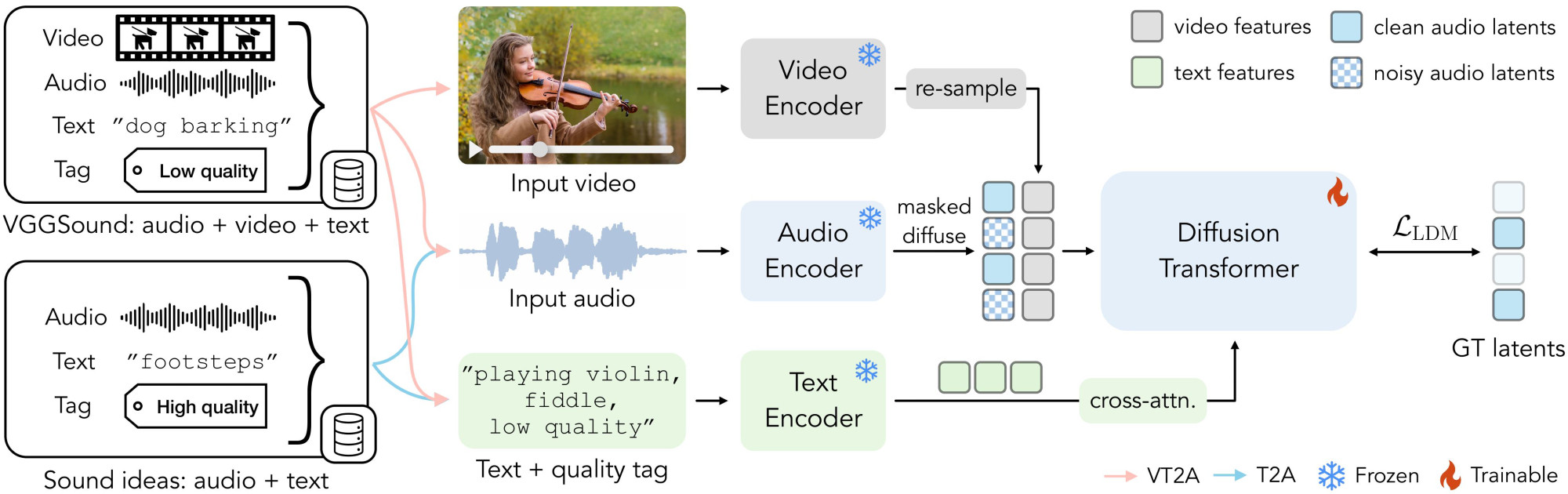
We jointly train our model on high-quality text-audio pairs as well as videos, enabling our model to generate full-bandwidth professional audio with fine-grained creative control and synchronization.
Comments
Log in with your Bluesky account to leave a comment
This work is done during my internship at Adobe Research. Big thanks to all my collaborators @pseeth.bsky.social, Bryan Russell, @urinieto.bsky.social, David Bourgin, @andrewowens.bsky.social, and @justinsalamon.bsky.social!

Comments