
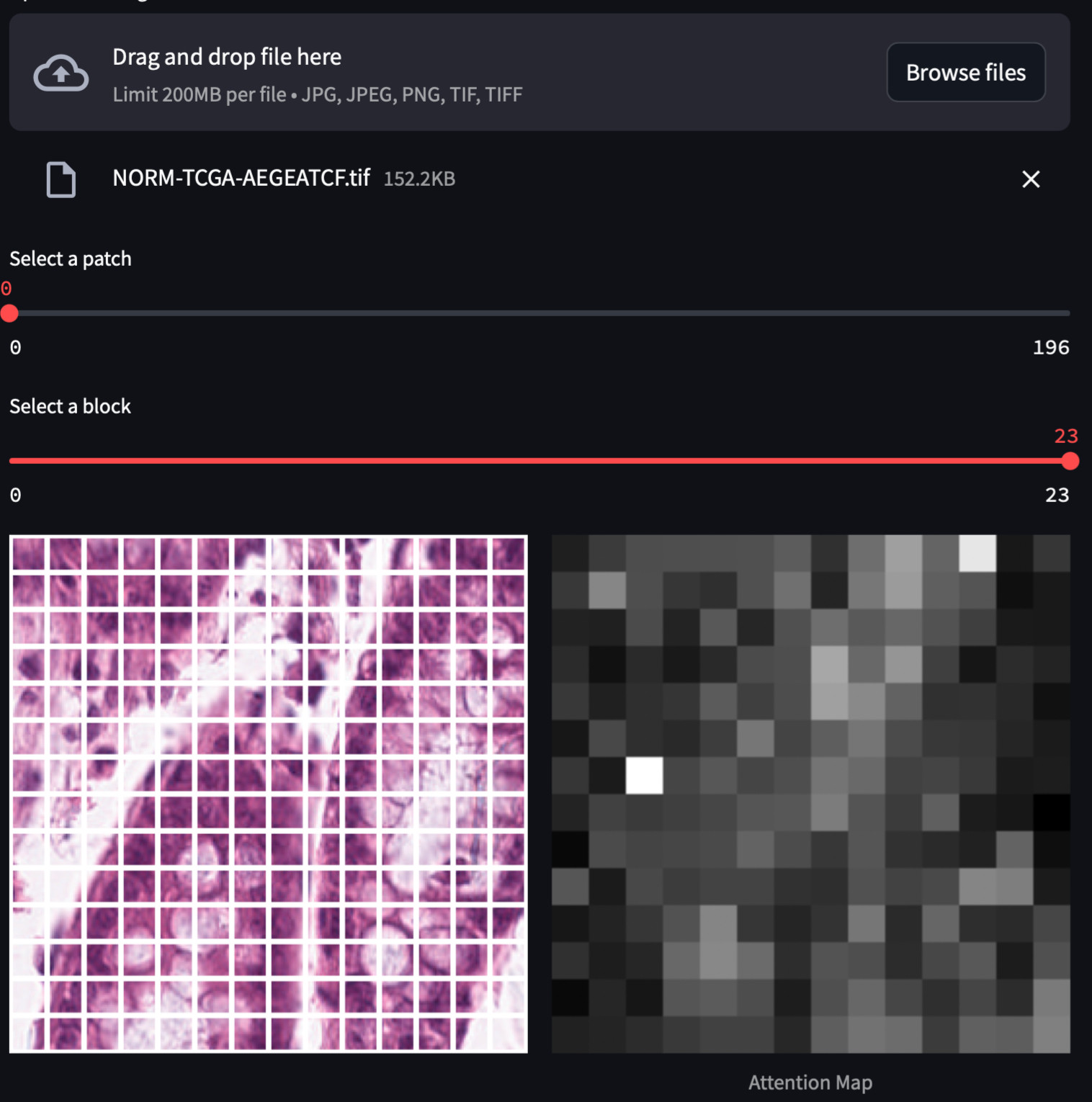
The model's image representation is very strong for segmentation but attention visualization of the CLS token cannot show you the objects in the image like DINO V2 trained on ImageNet. Funny fact: This model's CLS token also attends to the bird if you give an image of a bird 😂
Comments