
We released the OLMo 2 report! Ready for some more RL curves? 😏
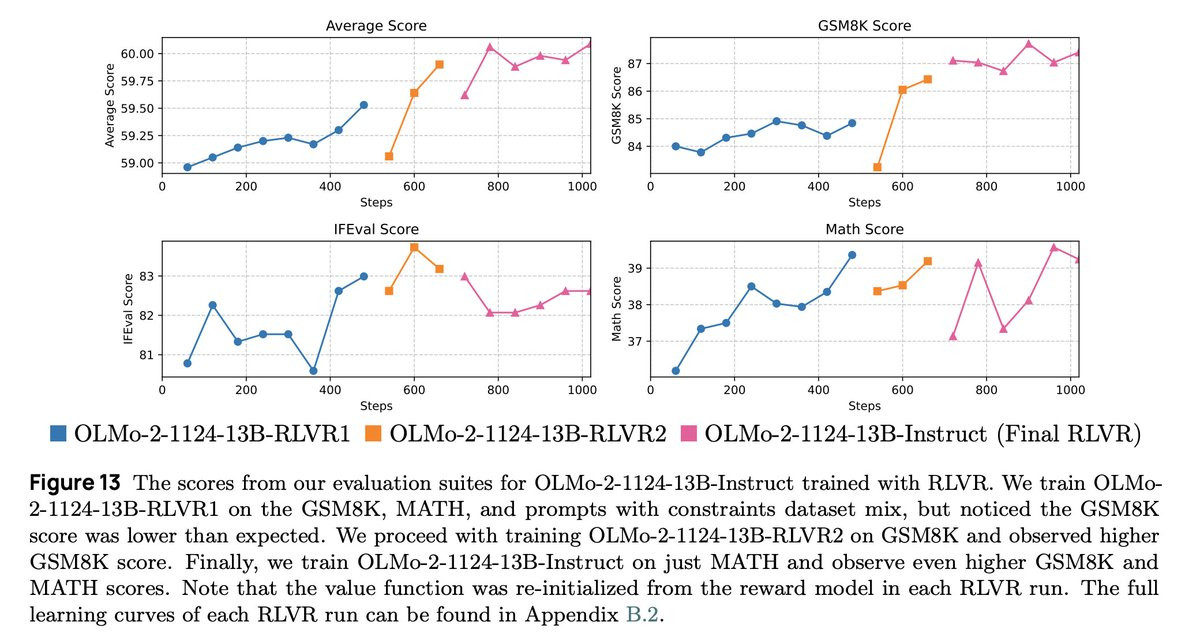
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
Comments
🤡 Basically, we didn't use HF's fast tokenizer, so the instruct models' tokenizer apply pre-tokenization logic differently from the base models.
So, we decided to re-train the models using the correct tokenizer.
Our initial reproduction attempt shows regression on SFT / DPO / RLVR.
Our final RLVR checkpoint does look pretty good 😊