
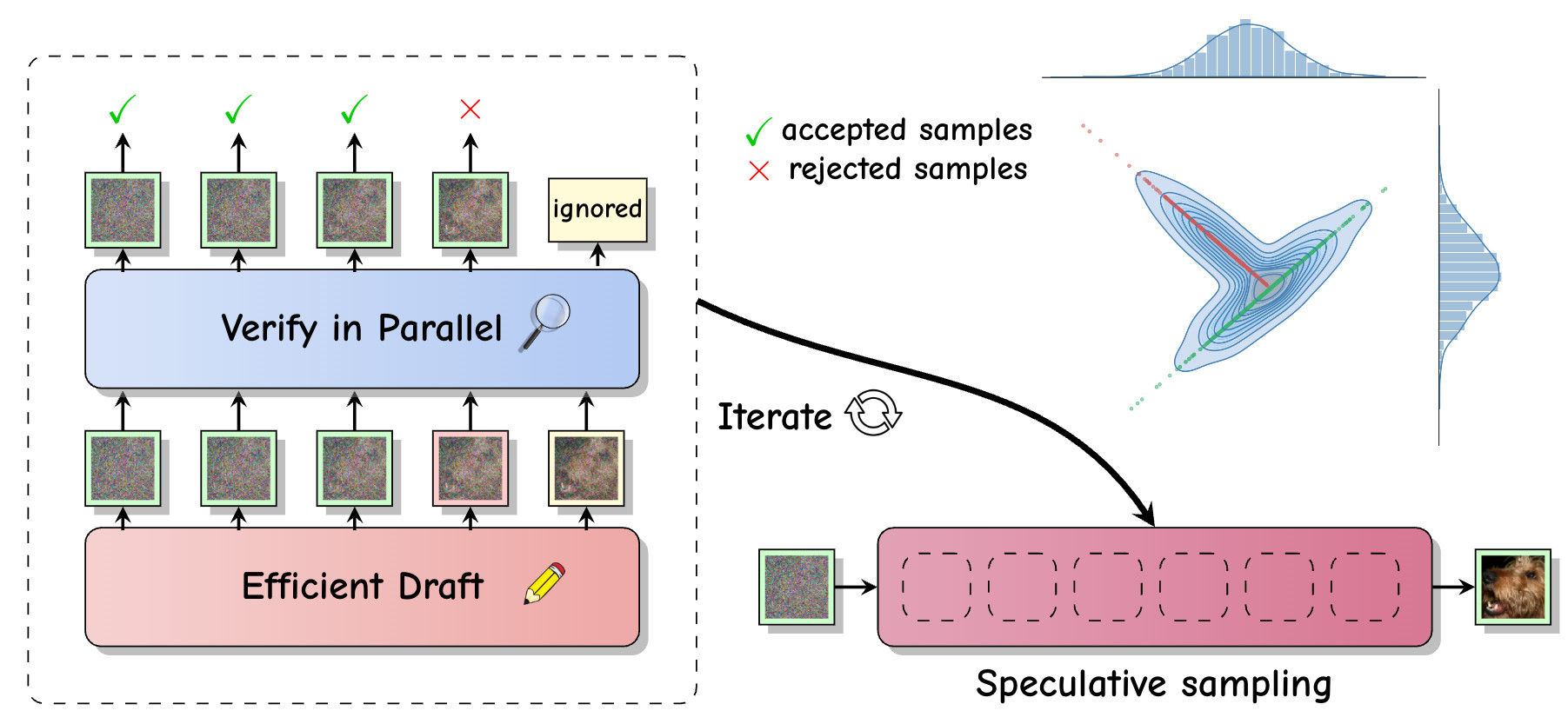
Speculative sampling accelerates inference in LLMs by drafting future tokens which are verified in parallel. With @vdebortoli.bsky.social , A. Galashov & @arthurgretton.bsky.social , we extend this approach to (continuous-space) diffusion models: https://arxiv.org/abs/2501.05370
Comments