
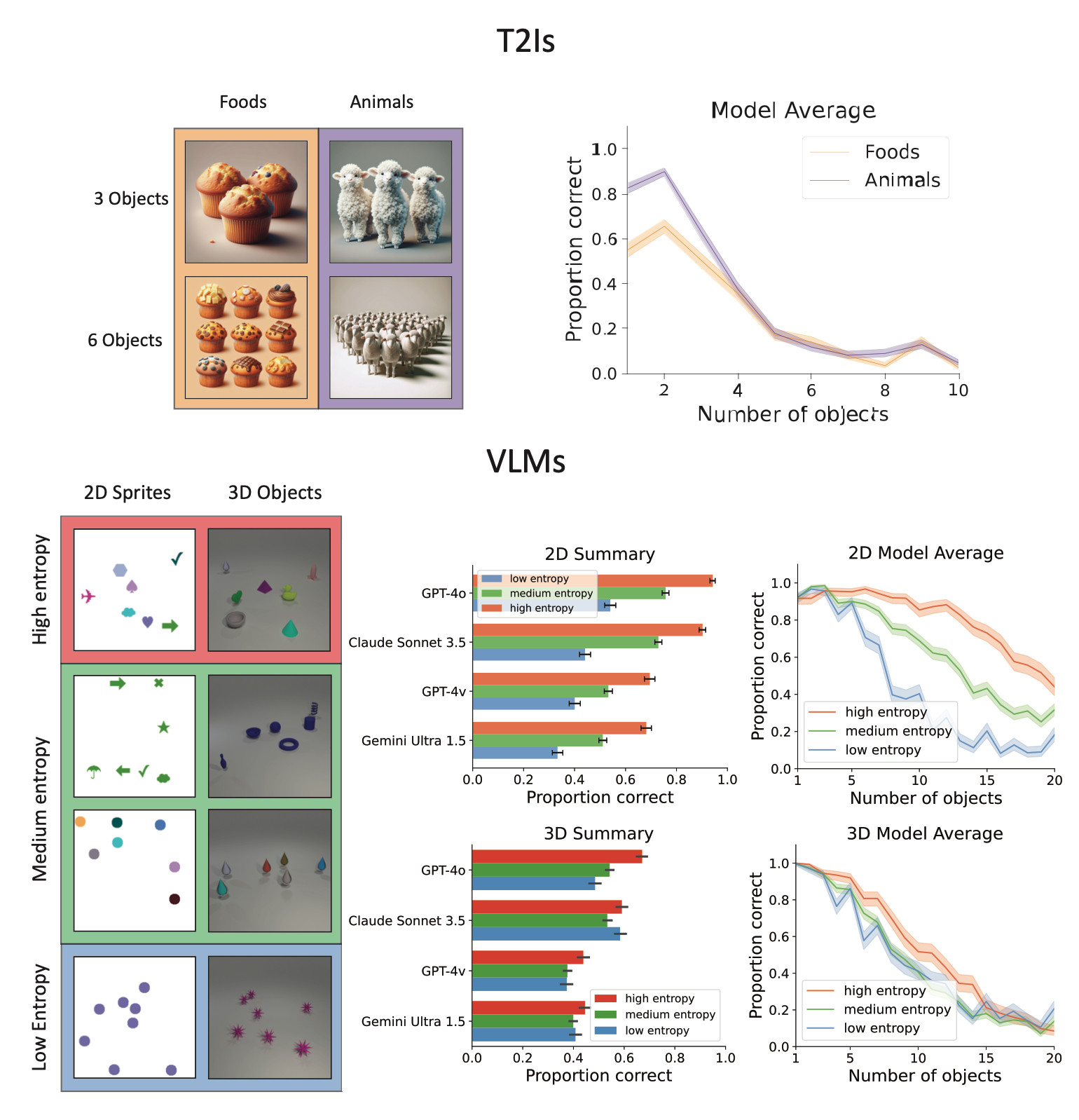
(4) Both multimodal LMs & text-to-image models show strict capacity limits - similar to human 'subitizing' limits during rapid parallel processing. Key finding: They improve with visually distinct objects, suggesting failures stem from feature interference.
Comments