
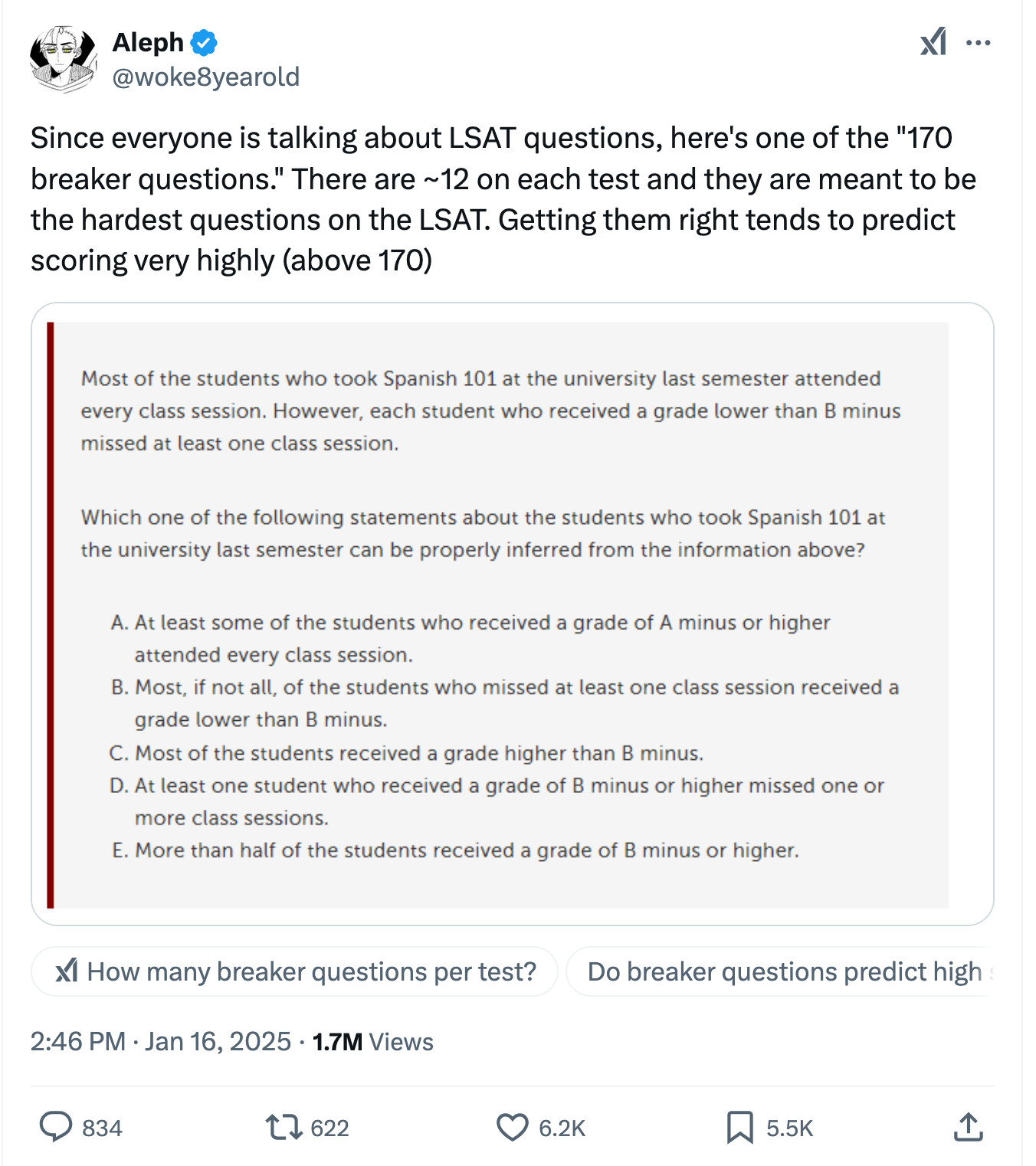
I tried this on GPT-4o, o1, o1-mini, o1-pro, Claude 3.5 Sonnet, Claude 3.0 Opus, Gemini 2.0 Experimental Advanced, Gemini 2.0 Flash Thinking Mode, DeepSeek-V3, and DeepSeek-V3 w/DeepThink.
Every "reasoning" model got it right. Every other model got it wrong. Seems notable.
Every "reasoning" model got it right. Every other model got it wrong. Seems notable.
Comments