
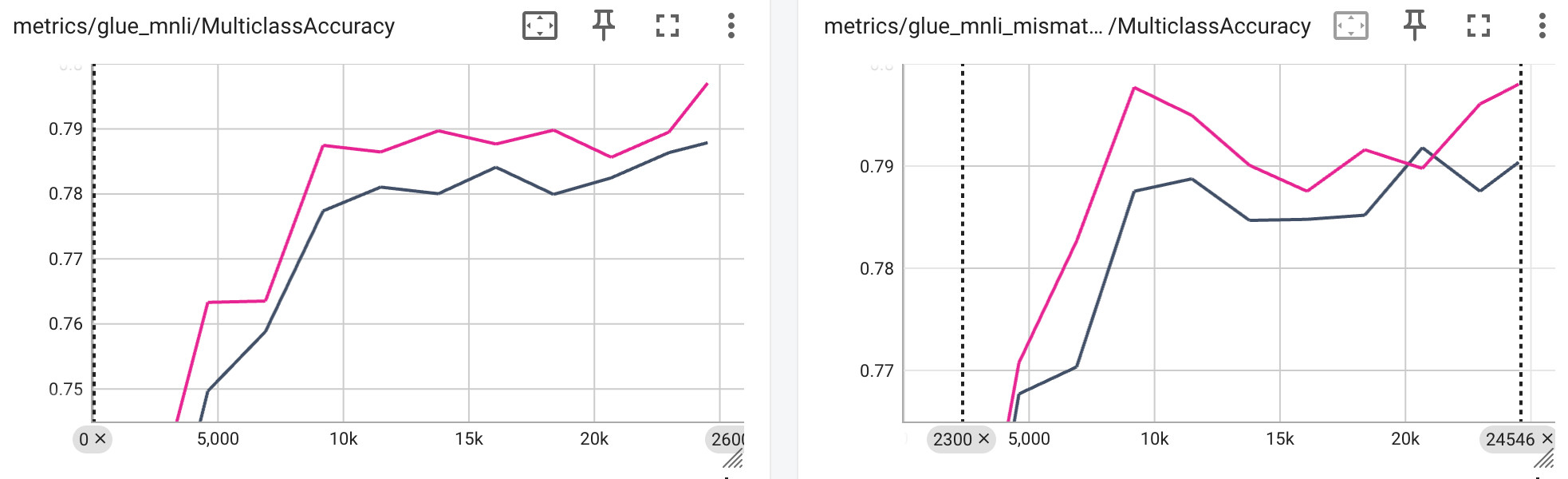
Comparing my new BERT-like model (pink) v. Transformer ++ BERT both pre-trained on ~30M samples and fine-tuned on MNLI. This is super promising and there is likely still more to gain in future iterations. Looks like a full training run and research report are going to be filling my weekend.
Comments