So now let's translate this procedure into estimating equations. First is our logistic regression model for R|X. This is simply the same as the previous post
Comments
Log in with your Bluesky account to leave a comment
Step 2, is simply computing the weights (which doesn't need it's own estimating equation). Step 3 is a weighted regression model. While we haven't done weighted regression yet, it is simply the product of the weight with the estimating function. Below presents these stacked together
Step 4 is again just predict some values from the model (doesn't require an estimating equation), so we only need Step 5. Step 5 is simply the mean of the predicted values from the outcome model (like for g-computation usually). The following is the full stack
Again we can use the sandwich for variance estimation
Those of you familiar with AIPW or doubly robust methods might know that we can also use a influence function (IF) variance estimator. So you might wonder why bother with the sandwich here
The IF variance assumes that both models are correct. So our point estimator is doubly robust but the variance estimator is NOT. To me, this diminishes the motivation behind using doubly robust estimators...
To me the beautiful thing about the DR estimator is you can get away with estimating both nuisances at slower rates (as long as the product is < 1/sqrt(n))
This opens the door to using much more flexible methods - random forests, lasso, ensembles, etc etc
I don't disagree with you. My statement was following from use of parametric models for the nuisance functions (which remains common in epi). Yes, DR offer a big advantage in more flexible modeling and their use has increasingly picked up for that feature
I find it much more believable that I could estimate both nuisances consistently, but at slower rates, vs that I could pick 2 parametric models (without looking at data) & happen to get one exactly correct

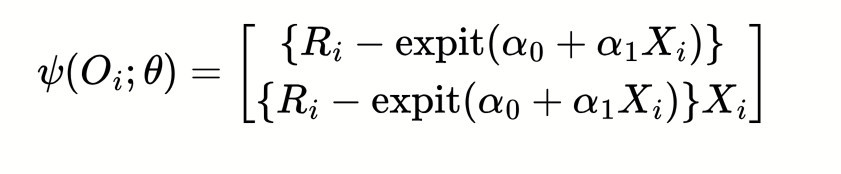
Comments
Those of you familiar with AIPW or doubly robust methods might know that we can also use a influence function (IF) variance estimator. So you might wonder why bother with the sandwich here
You can read more details in the following pre-print
https://arxiv.org/abs/2404.16166
To me the beautiful thing about the DR estimator is you can get away with estimating both nuisances at slower rates (as long as the product is < 1/sqrt(n))
This opens the door to using much more flexible methods - random forests, lasso, ensembles, etc etc