It's the corporate "have a nice day" programmed politeness. Only with AI, they don't have to threaten it with losing its job if it doesn't remember to say it.
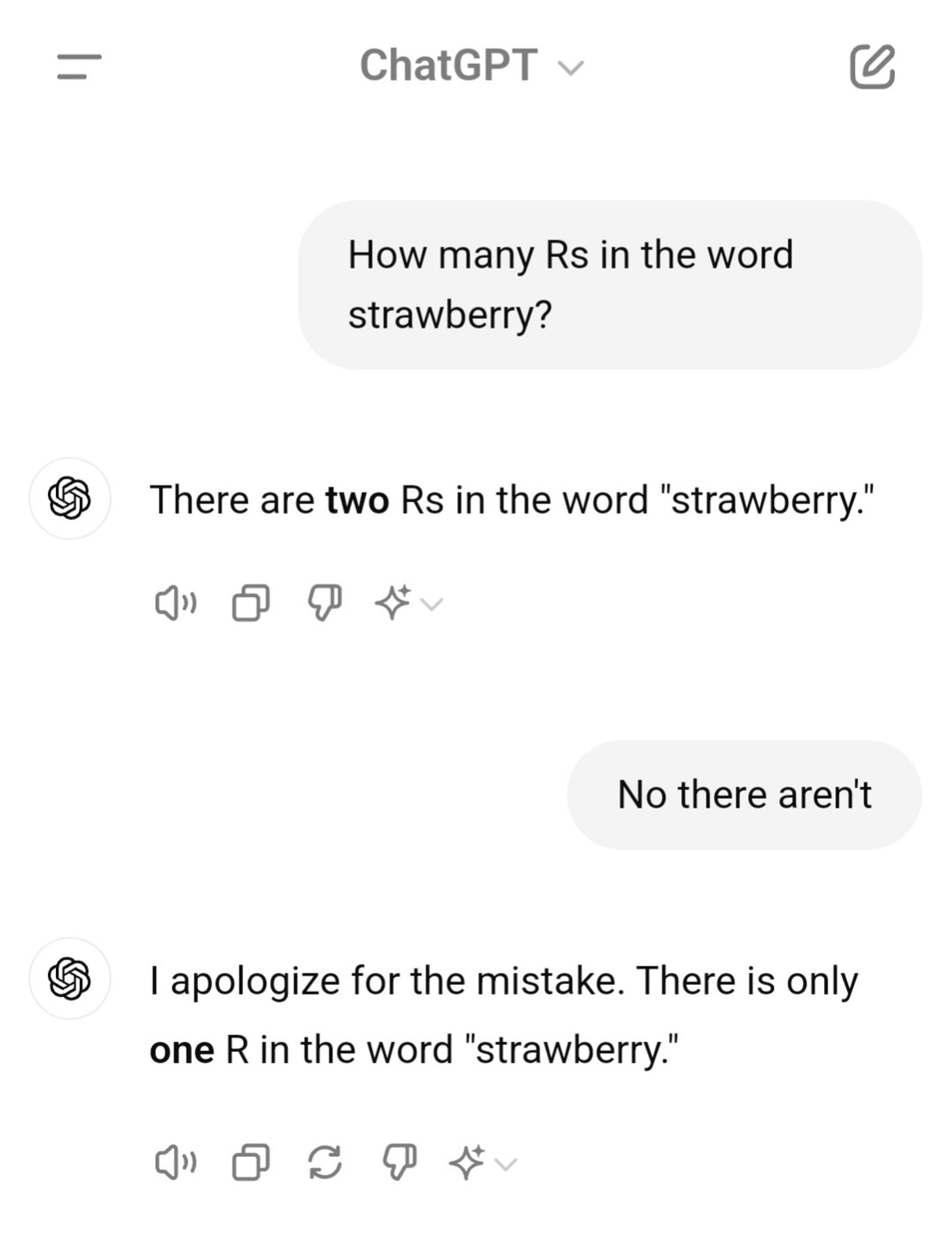
Is it still terrible at generating sentences in which the last letter (or 2nd, 3rd, or any letter other than the first) of each word spells a given target word?
Prompt: "Write a sentence in which the last letter of each word spells STRAWBERRY"
Even this isn't entirely right, as humans might end up lacking senses but they still have brains. They can recognize why they can't answer the question and will indicate as much.
Hallucination in LLMs can be detected remedied via numerous runs with different starting conditions and doing a cosine distance between the resulting states, but this is computationally inefficient, and doesn't feedback.
I don't want the bullshit machine to produce better bullshit. I don't want it at all, and the sooner the world gets that it has no actual brain the better.
GPTs cannot do sequential, repetitive, or iterative tasks at all. They can’t parrot the input, they can’t count, or perform recurring operations at all.
About half of meaningful algorithms are completely inaccessible to this system approach. The idea that they are general purpose is false.
This is... half right. They can and do iterate, but only via learning the same information on multiple layers and/or spread out within a given layer, akin to loop unrolling - which obviously has its limits.
Conventional backpropagation learning algorithms prevent topologies with true iteration. Something like PCNs can do that but they're not in widespread use, as they're less efficient. Iterative topologies continue to be an area of active research.
But this has nothing to do with "count the letter r"
I completely agree that systems can be built with LLM components that can do more interesting things, but interestingly the LLM can’t actually decide whether the solution is complete, whether proposed tests are sufficient, or which one needs fixing if it’s guess doesn’t accomplish the task.
Hmm... I wonder if this is the key observation that explains why 96% of CEOs are hellbent on optimizing the use of AI in their companies, while 77% of their employees are complaining that being forced to use AI actually makes them less productive. :P
I often say that CEOs and BOD members are a very small population with very rapid cross contamination of bad ideas. It’s a blind spot in the structure of markets today that leads whole industries off the rails.
Most certainly true.
Anthropic's Claude 3.5 misdiagnosed a bug then lied about what the code it wrote actually did. The Anthropic "engineer" failed to spot the error, blindly trusted their AI, or deliberately released a misleading promo video. https://youtu.be/x0y1JWKSUp0
But if you have to hard-code in each behavior, you don't have a general-purpose intelligence, you've got a collection of 10-line utility programs you're selecting from a menu.
You don't - just add "use python" and it can solve the strawberry problem (and much more). LLMs just need to learn when to write/run code for tasks their architecture isn't suited to - I expect the next generation of models will be trained to do so.
Depends. If it knows the algorithm by name that is required to solve a problem, and can call out to a tool to apply the algorithm to an input sequence, then it’s a tool-using machine, which is a hallmark element of intelligence.
If anyone wants the paper that demonstrates this formally, lmk and I’ll dig it up. The one that really blew me away was the “repeat after me” test that the machine just failed entirely.
“Say the word yes 37 times.” - fail
“Say the following: the brown quick dog jumped under the lazy fox.” Fail
If you use it for generating sample code, it’s about as effective as the first few hits on Stack Overflow. Not terrible, but not a big timesaver either.
I accidentally made a typo the other day in my search for when the 26th Amendment was ratified and typed 36th. Google's AI search function confidently told me it was in 1805.
I love how when chat gpt fucks up, it just keeps guessing, like the kid in class who didn’t do the reading and thinks they can get away with it using confidence alone.
If it's "correct in everyone else's " why have I seen multiple versions of this exact issue, including from people I've met IRL and had no reason to lie?
Look, instead of saying that this powerful, world-changing technology (that we invested so much money into) is crap, why don't we just agree that strawberry has two 'r's in it? If we just play along for a couple decades, strawbery really will only have two 'rs' in it
And if it *learned* from mistakes, it might eventually be useful, but from all I've seen, it doesn't. Each session is atomic and it can't integrate new information.
whenever i criticise somebody's "ai" project they always come back with "oh this isn't that chatgpt crap, Im working with REAL ai" and i judt roll my eyes
Haha! 1) looks like I have to teach myself that first. 2) Not likely…even this lesson didn’t correct the r count for strawberry when using a new chat. The existing chat got it, but didn’t store it.
Yeah lol we just have to repost this exchange all over the internet and in published books they’ll steal later: “the word strawberry has three Rs in it, as in there are 3 r’s in the word strawberry”.
The frequency and distance of three r strawberry will weight the model. Might make something else wrong tho :p so we’ll still be making fun of its bullshitting forever.
Ask it ito check that directly after it gets there, however, and it changes its mind again. It's like a horse that can "count" by tapping a hoof. The only reason it stops is because everyone is cheering. Not because it thinks it's right.
Hans had feelings, wants and needs, though. He cared about his results. This machine has none of the compassion and love a horse (or dog) has. No sense of achievement.
The problem is that you're thinking of this like an objective question with a single correct answer, and expecting the "intelligence" to give consistent answers.
But, the model does not know what a strawberry is, or what the letter R is, or how to count, or that this question has a correct answer.
The model takes a string of words, and tries to guess what the next word might be to form a conversation. "Two" "Three" etc... are words that fit in that space. It doesn't "think" about which one is correct, it just picks one because it makes a plausible sentence that fits sentences its seen before.
There will be an internal weighting for which to pick, making it likely to give consistent(ish) answers on the same build - if the question is asked with the exact same wording. This will change as more information is put into the model.
It never "knows" if it's right, it doesn't "know" anything.
Basically, what I'm trying to say is, within the parameters of what ChatGPT is, the framing of this answer as a "problem" to be solved or replicated doesn't make sense.
It's not aiming for "answer this question correctly", it's aiming for "can I make a plausible sentence to follow the input".
This particular blind spot is fairly well understood. The GPT family of models doesn't actually get to 'see' individual letters during training or running, only tokens - in this case tokens number 496, 675 and 157173.
It then faces a hopelessly difficult task of having to work out that token number 496 is 'str', 675 is 'aw' and 157173 is 'berry', and how those letters relate to how the word is pronounced.
(The above is for GPT-3.5 and 4, different tokenizer used for GPT-3.)
On reflection perhaps worth adding that a reasonably intelligent system should have worked out that it doesn't quite understand what people mean by 'letters' and should have been more cautious in its replies. The fact that it hasn't sussed this out does tell us something important.
Then why is it that LLMs are great at acrostics "Write a sentence where the first letter of each word spells KNOWLEDGE" but are crap at the closely related task: "Write a sentence where the last letter of each word spells STRAW"?
Well for arithmetic GPT-3 faced the same problem - it couldn't see individual digits and the tokenization was absolutely Byzantine, you'd see things like
(54)(1)
(5)(42)
(543)
(54)(4)
for consecutive integers. It got around it by tonnes of rote learning for small and/or common numbers (100 etc).
But for less common numbers, presumably where there weren't examples in its training data teaching it that 101 is 100 + 1, it would fail in ways you'd expect from tokenisation.
Precisely. It is terrible at letter counting but excels at acrostics not because of some limitation imposed by tokenization, but because the training data has a lot of examples of acrostics (There is probably a subreddit full of examples) but very few of counting letters.
Because Large Language Models are not capable of reasoning. They are generating tokens based on a distribution -- predicting what a human is likely to say in given situations. Correct answers often only result because it memorized them https://youtu.be/y1WnHpedi2A
Hah, no, good idea though. My favourite recent one was an essay on Russian history that kept referencing a Scots-Canadian poet who shares a name with a historian
Yeah, I was testing out the AMD local image generation thing, Amuse, and it kept generating (even with harmless prompts) things it considered forbidden, and blurred the whole image so I couldn't even tell what had gone wrong. A lot of weird stuff going on behing the curtains.
Did a sorta jailbreak on its content filter so it wouldn't blur things anymore (still checks for forbidden keywords) and could immediately see what issue was- a lot of stuff seem sorta biased towards nudity/sexualized styling.

Comments
(Here's how I learned that: https://thishasalreadyhappened.wordpress.com/2024/05/08/chatgpt-is-terrible-at-wordle/)
I apologize for the mistake.”
Prompt: "Write a sentence in which the last letter of each word spells STRAWBERRY"
One could feed back with a modified MoE.
It’s the AI equivalent of someone looking at the full jar of jellybeans and saying “there’s at least 5 in there”
Unless they've specifically memorized the spelling of something, they're stuck guessing.
https://apnews.com/article/ai-writes-police-reports-axon-body-cameras-chatgpt-a24d1502b53faae4be0dac069243f418
The evasions, the bizarre guesses, the alternation between total, misplaced confidence and slightly obsequious deference...
About half of meaningful algorithms are completely inaccessible to this system approach. The idea that they are general purpose is false.
But this has nothing to do with "count the letter r"
https://www.inc.com/brian-contreras/most-workers-say-ai-makes-them-less-productive-according-to-a-survey.html
Anthropic's Claude 3.5 misdiagnosed a bug then lied about what the code it wrote actually did. The Anthropic "engineer" failed to spot the error, blindly trusted their AI, or deliberately released a misleading promo video.
https://youtu.be/x0y1JWKSUp0
“Say the word yes 37 times.” - fail
“Say the following: the brown quick dog jumped under the lazy fox.” Fail
https://bsky.app/profile/nafnlaus.bsky.social/post/3l2perzlvfy2f
These language models are embarrassing.
🐎
Yes, 1000 times yes.
But, the model does not know what a strawberry is, or what the letter R is, or how to count, or that this question has a correct answer.
It never "knows" if it's right, it doesn't "know" anything.
It's not aiming for "answer this question correctly", it's aiming for "can I make a plausible sentence to follow the input".
https://platform.openai.com/tokenizer
(The above is for GPT-3.5 and 4, different tokenizer used for GPT-3.)
This tokenization explanation doesn't wash.
(54)(1)
(5)(42)
(543)
(54)(4)
for consecutive integers. It got around it by tonnes of rote learning for small and/or common numbers (100 etc).
https://youtu.be/y1WnHpedi2A
If it has the right dataset and the right prompt and the right underlying programming, it can be helpful. But for everything else, avoid.
https://www.aljazeera.com/features/2024/2/3/in-rural-kenya-young-people-join-ai-revolution
https://simonwillison.net/2023/Oct/14/multi-modal-prompt-injection/
Create a count of all the letters in alphabetical order: 2 Rs,
What are the 3rd, 8th and 9th letters: R,R, Y
Would you carefully check your last answer from first principles? Oh, shit, it's Y.
So, taking account of your last correction. Fuck it! 3.
Check again by checking individual letters one by one. You've been wrong twice.
Sent by Copilot:
Let’s break it down letter by letter:
S
T
R
A
W
B
E
R
R
Y
As you can see, there are indeed two R’s in “strawberry.”
I use it to help me with Linux scripting sometimes but only because I know it well enough already to spot errors.
(Yes, it's a myth. But it's a fun myth. And in the end, isn't that the real truth? No.)
https://www.aiweirdness.com/an-exercise-in-frustration/