
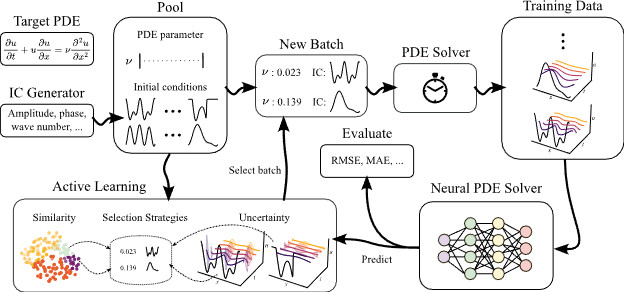
Neural surrogates can accelerate PDE solving but need expensive ground-truth training data. Can we reduce the training data size with active learning (AL)? In our NeurIPS D3S3 poster, we introduce AL4PDE, an extensible AL benchmark for autoregressive neural PDE solvers. 🧵
Comments
- Parametric PDEs such as incompressible Navier-Stokes
- Surrogate models (U-Net, FNO, SineNet).
- AL algorithms such as SBAL, CoreSet, or LCMD. 4/