Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks.
Comments
Log in with your Bluesky account to leave a comment
Oh, cool. That seems like the sensible way to do it, since I'm guessing image analysis still has the familiar limitations and json just makes the structure less clear. Although I don't know if that would be a problem for it anymore. It would be for a human.
Thanks for posting the cost efficiency. I'm not seeing anyone talking about the fact that o3 Low costs an OoM more than o1, and o3 High costs three OoMs more. Yes, this is an impressive feat, but I'm beginning to doubt OpenAi's commitment to "intelligence that is too cheap to measure."
I'm not so cynical as to think that they just did it for a particular benchmark, but yes, I'm assuming it is a tuning of GPT4, not based on an entirely new pre-training run. My guess is that they have learned some tricks to make it get more out of increased test-time compute.
Same. Additionally, it is possible that scrapping hard, you might have accidentally trained on some quiz which has some overlap with ARC. I don't know how data scrapping works at the scale of OpenAI, but I suspect no one can control it that well.
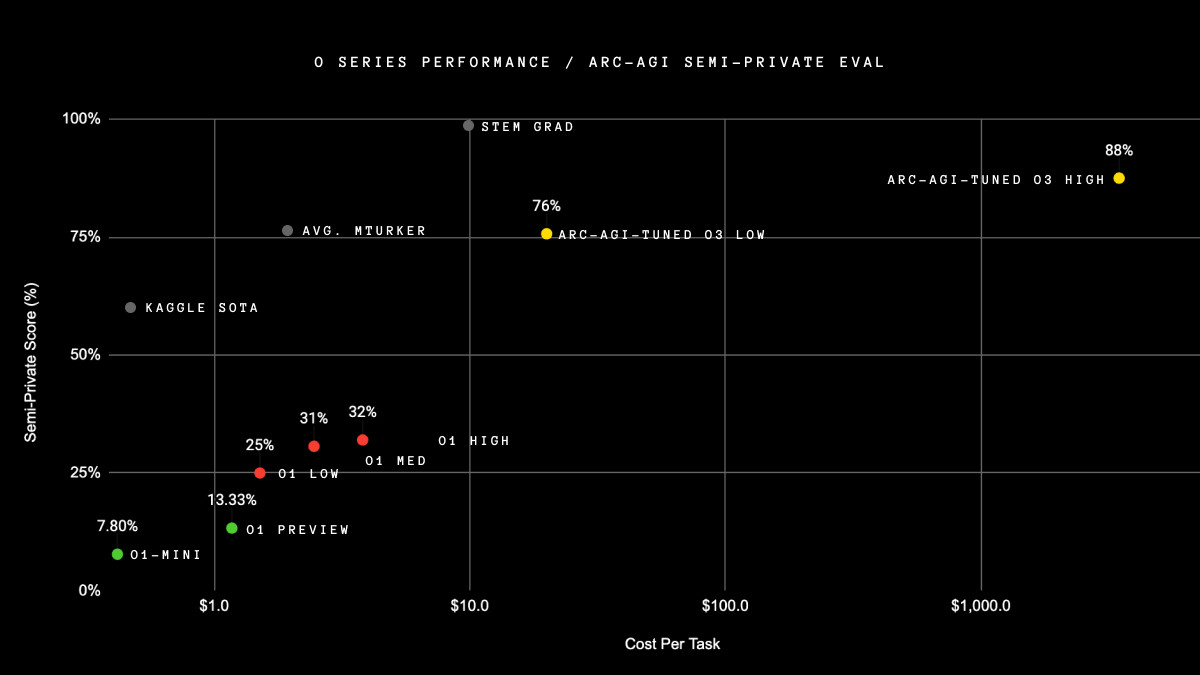
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task in compute ) and 87.5% in high-compute mode (thousands of $ per task). It's very expensive, but it's not just brute force -- these capabilities are new territory and they demand serious scientific attention.
The website is unreadable, sorry. If you have something to say to humans post a black on white static text on a web-page.
And I'm grave serious, get real.
Thanks for the writeup! Is there more you can say about the "tuning" of o3? Was it specifically finetuned on the public dataset or was the public dataset just part of the training corpus? I guess the line here is a bit blurry.
Sooo they win the grand prize just 10 days before the end of the year, yeah? 88% > 85% :(. Will they be getting the award money? That’s a pretty damning moment for the future of FOSS, if so… regardless, really.
Also, this makes it even more ludicrous that OpenAI is still denying they’ve passed AGI, so as to not trigger the doomsday clause (“give away everything”) in their articles of incorporation. This benchmark was specifically designed to test general human reasoning…
ARC it's not bullet proof. You can look at the public set, then put 12 people in a room for some weeks, and they can produce tests which, most likely, will end up having some overlap with the private test set that they have not seen. I still don't see how DL can "reason" outside the training data.
what's the expected score of o3 for ARC-AGI-2? will you be adapting v2 in terms of its perfomance? tbh, i suspect openai might be targeting those kinds of benchmarks on purpose, especially since every new version of gpts fares worse than its predecessors on some tasks, like gpt4 turbo for instance.
anyway, looking forward to reading your full analysis of o3's performance! i realise my previous comment was mean-spirited and presomptuous towards openai. so i'm genuinely interested in your opinion about this! have a good day/evening
Can you please clarify what's the basis for the "retail price" column? Is that a) the OpenAI API cost (something like o1 it's $60 per million token), or b) raw GPU costs?
The math works for a) $60 per million x 55k token per sample x 6 sample per task = $19.8 per task.
Were you given access to the Chain-of-Thought transcripts from o3 running on ARC-AGI? Would be really interesting to see what type of reasoning it's doing
That's why it's semi-private. That set is not publicly exposed, but whoever is monitoring their API calls can harvest the tests, and it's no longer private.
I think the private is only run on the ones which are open source.
It sounds like you actually believe that a probabilistic approach to AI is eventually going to achieve acceptable levels of accuracy / reliability, which is irrational nonsense.
This chart is basically saying that the o3 models fine tuned on "ARC-AGI" problems do better answering "ARC-AGI" problems than older models without that fine tuning. Is that correct?
It’s truly amazing that it took 4 years to get to 5% & then in one year to 87.5%
I think most probably o1 helped OpenAI to create high quality synthetic reasoning dataset similar to Arc AGI tasks to get this huge jump from o1 to o3, but it completely changed my perspective towards test-time scaling
A smaller open source model running on less than .10$ per task managed 56% on arc-agi. O3 used 30,000x as much compute to get 88%. Wouldn't be surprised if used similar methods, with difference being compute. Openai did train the model for this domain.
No one know for sure! On the Arc benchmark results they mentioned that they used O3 “tuned” version which probably means that they have fine tuned it on Arc training tasks and used O1 for generating synth data similar to ARC dataset
I may be wrong, but this is a mis-use of the word "reasoning", no? reasoning means *understanding* and deduction from understanding. There remains no actual understanding.
How do you know that? I mean, do we really have a philosophically rigorous definition of “understanding” and “reasoning” such that we can definitely say these models have neither?
I may be wrong, but I think so, yes, and unequivocally. If I build lego machine which constructs lego machines, we could see how it was working and why. We wouldn't think reasoning was involved. With what now termed AI, how it works is known, and it is not reasoning, any more than a lego machine is.
I don’t think there’s a slam dunk argument either way—and I used to be lean much harder towards your position when I studied philosophy of mind in undergrad—but I don’t think intuitions about simple lego machines are sufficient to tell us about neural nets with billions of weights
But this seems like a combination of two things - that these machines are producing behavour which is thought-like, rather than mechanical-like, and that how they work is unknown. I would say though how they work is known in the larger sense (or indeed how could they be constructed).

Comments
https://anokas.substack.com/p/llms-struggle-with-perception-not-reasoning-arcagi
I have no trouble imagining them targeting specific benchmarks.
Until the model can tune itself to arbitrary tasks in realtime, that shouldn't count.
And I'm grave serious, get real.
Can you clarify what exactly the “samples” are? Are they basically N-shot? Or are they more like “max depth” for the generated CoT?
Hoping it’s not N-shot, that would make these results less impressive to me
In your understanding is o3 better understood to be a model, or an agent that includes a model?
Please click below ⬇️
Ugh. We’re so fucked 🥲
Can you please clarify what's the basis for the "retail price" column? Is that a) the OpenAI API cost (something like o1 it's $60 per million token), or b) raw GPU costs?
The math works for a) $60 per million x 55k token per sample x 6 sample per task = $19.8 per task.
I think the private is only run on the ones which are open source.
The data you shared seems to suggest it is brute force given that for 11.8% better accuracy you need to spend at least 50x more in compute.
Clearly things are going at best unpredictably and faster than you thought.
https://arcprize.org/
Please click below ⬇️
I think most probably o1 helped OpenAI to create high quality synthetic reasoning dataset similar to Arc AGI tasks to get this huge jump from o1 to o3, but it completely changed my perspective towards test-time scaling
But beyond that—yes, maybe a sufficiently complicated machine can reason. Our brains are extremely complicated biological machines, we can reason.