
I'm deleting this post because one of the researchers said the work shouldn't be extrapolated to all chatbots.
I guess I still want clarification, considering it says "Collectively, they provided incorrect answers to more than 60 percent of queries." But I run a fake news website so I will defer.
I guess I still want clarification, considering it says "Collectively, they provided incorrect answers to more than 60 percent of queries." But I run a fake news website so I will defer.
Comments
That's a problem, but it's not the same thing as stated.
Instead of being "wrong" AI is wrong in very specific ways.
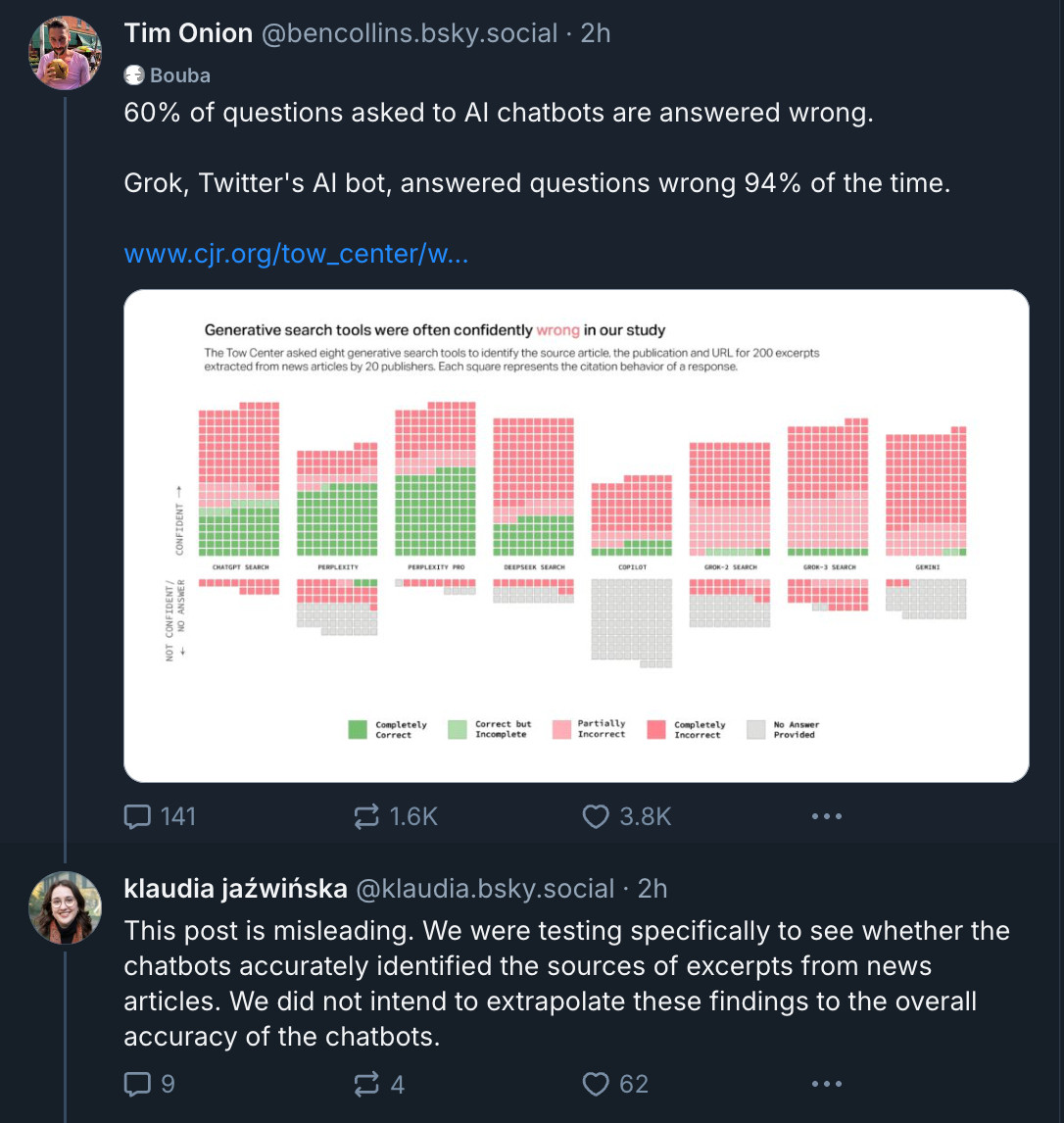
BUT: in the scope of the questions, the AI was actually WRONG (pink or red) most of the time, vs correct or simply not providing the answer.
Sometimes the AI couldn’t identify a source, and provided no answer. (That’s fine, actually.)
A majority of the time, the AI couldn’t properly cite the source and then provided WRONG data.
What Ben did was like taking an article saying “25% of lung transplants are rejected” and presenting it as “Study shows 25% of organ transplants are rejected.”
I can tell it is because it misleads you into thinking the graph is about when chatbots are "wrong" but the text is about lacking citations which is sort of "wrong" in a technical sense, but clearly not what is implied by the headline.
She has a valid point. A model (or model component) tailored to producing reference sourcing won't _necessarily_ perform the same as, say, a model/component that produces (arbitrary example) political leaning of the source.
BUT 1/
They're getting better at everything but they still can't model meta-knowledge of *why* they know those things
because, of course, they aren't human
Ben (aka Tim Onion) made it sound like the accuracy percentage applied to all kinds of questions. It was a very misleading representation of the results.
Testing LLMs for factual recognition is silly anyway. Like testing a walrus on tree climbing.
Of note, this was exclusively related to trivia about the film COCOON.
Sure seems subject to manipulation.
I mean, the error % is going to differ wildly depending on the query, right? Some types of questions bots are better at than others.
"AI Chatbots asked to identify excepts from news articles gave the wrong answer 60% of the time. Grok, twitter's AI bot, give the wrong answer 92% of the time to the same task. "
would be accurate. The question they are exploring is whether bots can cite sources. 1/
Link to article: https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php
The issue: if these bots can't locate sources given a precise quote from the sources (i.e. easy mode) then they are completely unequipped to cite their sources more broadly, which is fundamental to our ability to identify accurate information.
So when you type “I” the predictive text would helpfully suggest “hate”
The answer they provide is based on a probabilistic calculation of the most likely answer to your input.
A very useful talent, to be sure. The fact that they failed 60% of the time should prove to everyone why these pieces of crap are NOT ready to replace human employees on any level.
I only ever have these strokes of genius once in a while, but I guess integrity is still important in some places.
It looks nothing like me
We're living through real life parody after all